temporary spikes in memory usage should be handled by increasing CPU costs, not by aborting.
Basically if the GC sees memory pressure it informs the application that it should shed load. Once things are back to normal the GC informs the application that it can go back to its regular load.
这段话包含了Go语言的GC,在面对CPU和内存压力下的决策:
Go程序很少会OOM
这句话有一定前提,即内存设置是合理的,代码也没有明显的内存泄露问题
至于具体原因,我们看下文
业务高峰时内存使用率过高,应该通过提升CPU能力来解决,而不是中止程序
自动GC是需要CPU的计算资源做支持,来清理无用内存
要保证内存资源能支持程序的正常运行,有两个思路:
减少已有内存 - 通过GC来回收无用的内存
限制新增内存 - 即运行时尽可能地避免新内存的分配,最简单的方法就是不运行代码
显然,中止程序对业务的影响很大,我们更倾向于通过GC去回收内存,腾出新的空间
GC压力高时,通知应用减少负载;而当恢复正常后,GC再通知应用可以恢复到正常模式了
我们可以将上述分为两类工作
业务逻辑的Goroutine
GC的Goroutine
这两类Goroutine都会消耗CPU资源,区别在于:
运行业务逻辑往往会增加内存
GC是回收内存
这里就能体现出Go运行时的策略
内存压力高时,GC线程更容易抢占到CPU资源,进行内存回收
代价是业务处理逻辑会有一定性能损耗,被分配的计算资源减少
GC最直观的影响就体现在延迟上。尤其是在STW - Stop The World情况下,程序会暂停所有非GC的工作,进行全量的垃圾回收。即便整个GC只花费了1s,所有涉及到这个程序的业务调用,都会增加1s延迟;在微服务场景下,这个问题会变得尤为复杂。
type Reader struct { r io.Reader pad int64// Amount of padding (ignored) after current file entry curr fileReader // Reader for current file entry blk block // Buffer to use as temporary local storage
// err is a persistent error. // It is only the responsibility of every exported method of Reader to // ensure that this error is sticky. err error }
// children goroutine funcSubFoo(ctx context.Context) { for { select { case <-ctx.Done(): return case <-dataCh: go LongLogic() case <-finishedCh: fmt.Println("LongLogic finished") } } }
funcSubFoo(ctx context.Context) { for { select { case <-ctx.Done(): return case <-dataCh: // logic包内部保证 logic.Run() case result := <-logic.Finish(): fmt.Println("result", result) } } }
而logic包中的大致框架如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
package logic
var finishedCh = make(chanstruct{})
funcRun() { // 在这里引入排队机制 gofunc() { // long time process <-finishedCh }() }
funcSubFoo(ctx context.Context) { for { select { case <-ctx.Done(): return case <-dataCh: // logic包内部保证 logic.Run() case result := <-logic.Finish(): fmt.Println("result", result) } } }
而logic包中的大致框架如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
package logic
var finishedCh = make(chanstruct{})
funcRun() { // 在这里引入排队机制 gofunc() { // long time process <-finishedCh }() }
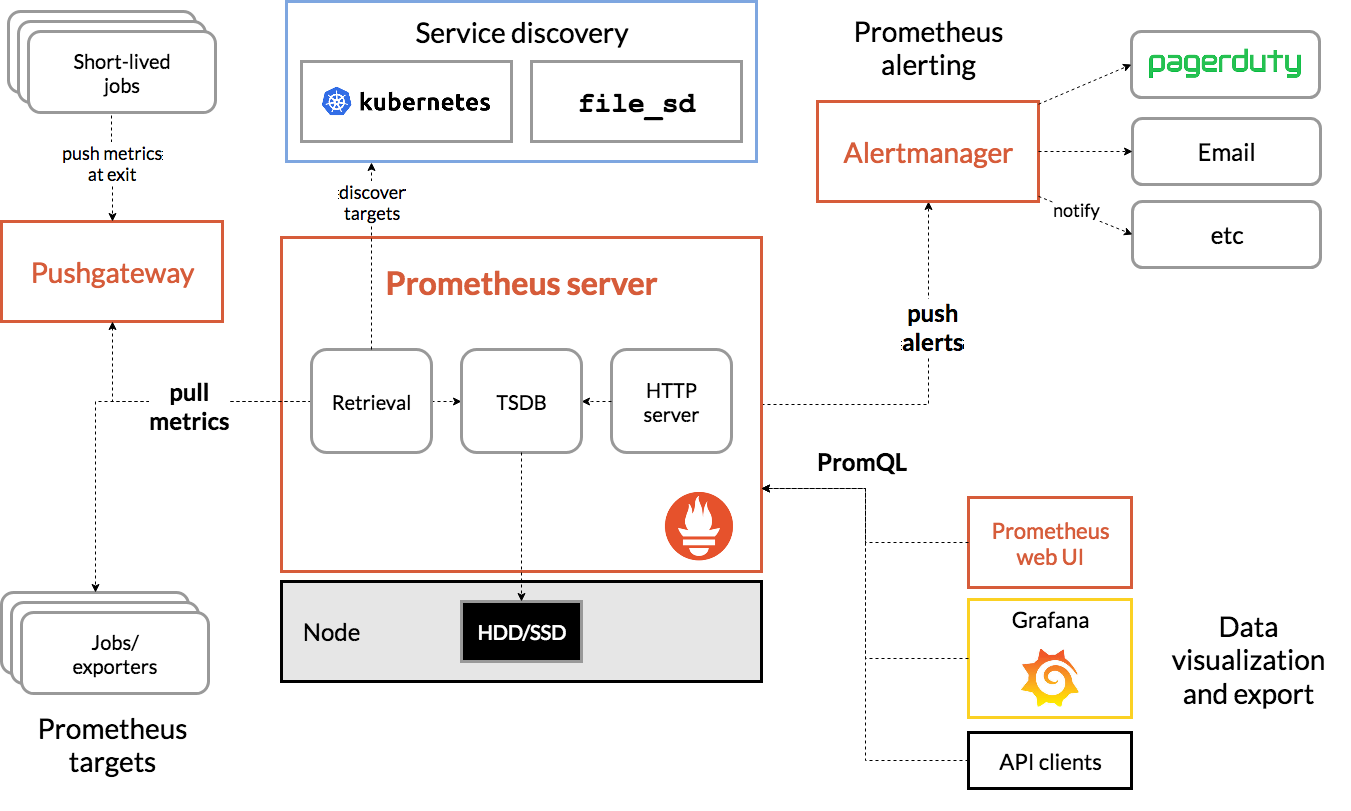
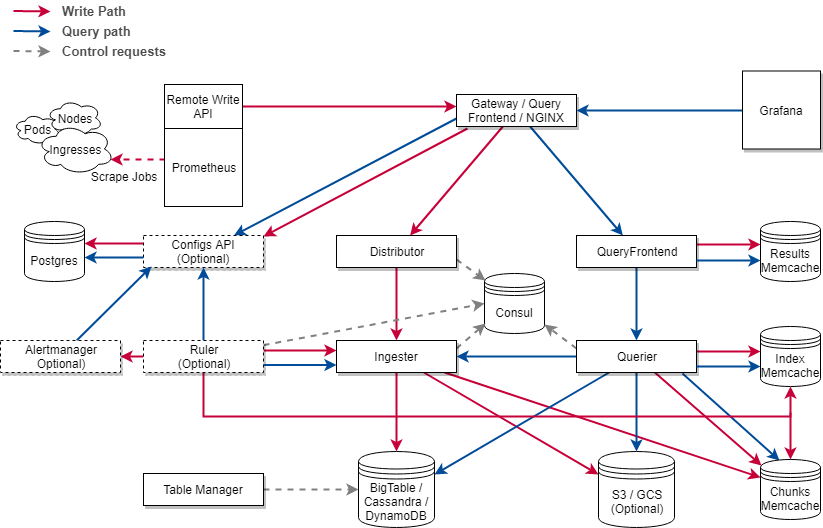
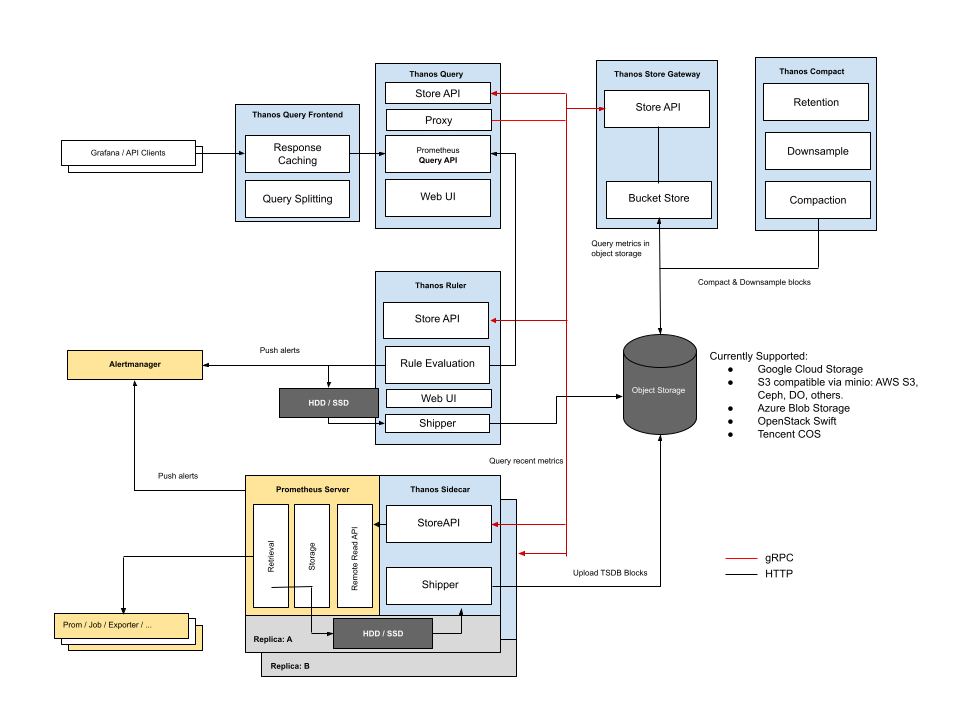
多维度数据Dimensional data - Prometheus implements a highly dimensional data model. Time series are identified by a metric name and a set of key-value pairs.
强力的查询Powerful queries - PromQL allows slicing and dicing of collected time series data in order to generate ad-hoc graphs, tables, and alerts.
很棒的可视化Great visualization - Prometheus has multiple modes for visualizing data: a built-in expression browser, Grafana integration, and a console template language.
高效存储Efficient storage - Prometheus stores time series in memory and on local disk in an efficient custom format. Scaling is achieved by functional sharding and federation.
简单操作Simple operation - Each server is independent for reliability, relying only on local storage. Written in Go, all binaries are statically linked and easy to deploy.
精确告警Precise alerting - Alerts are defined based on Prometheus’s flexible PromQL and maintain dimensional information. An alertmanager handles notifications and silencing.
很多客户端库Many client libraries - Client libraries allow easy instrumentation of services. Over ten languages are supported already and custom libraries are easy to implement.
大量现有集成Many integrations - Existing exporters allow bridging of third-party data into Prometheus. Examples: system statistics, as well as Docker, HAProxy, StatsD, and JMX metrics.
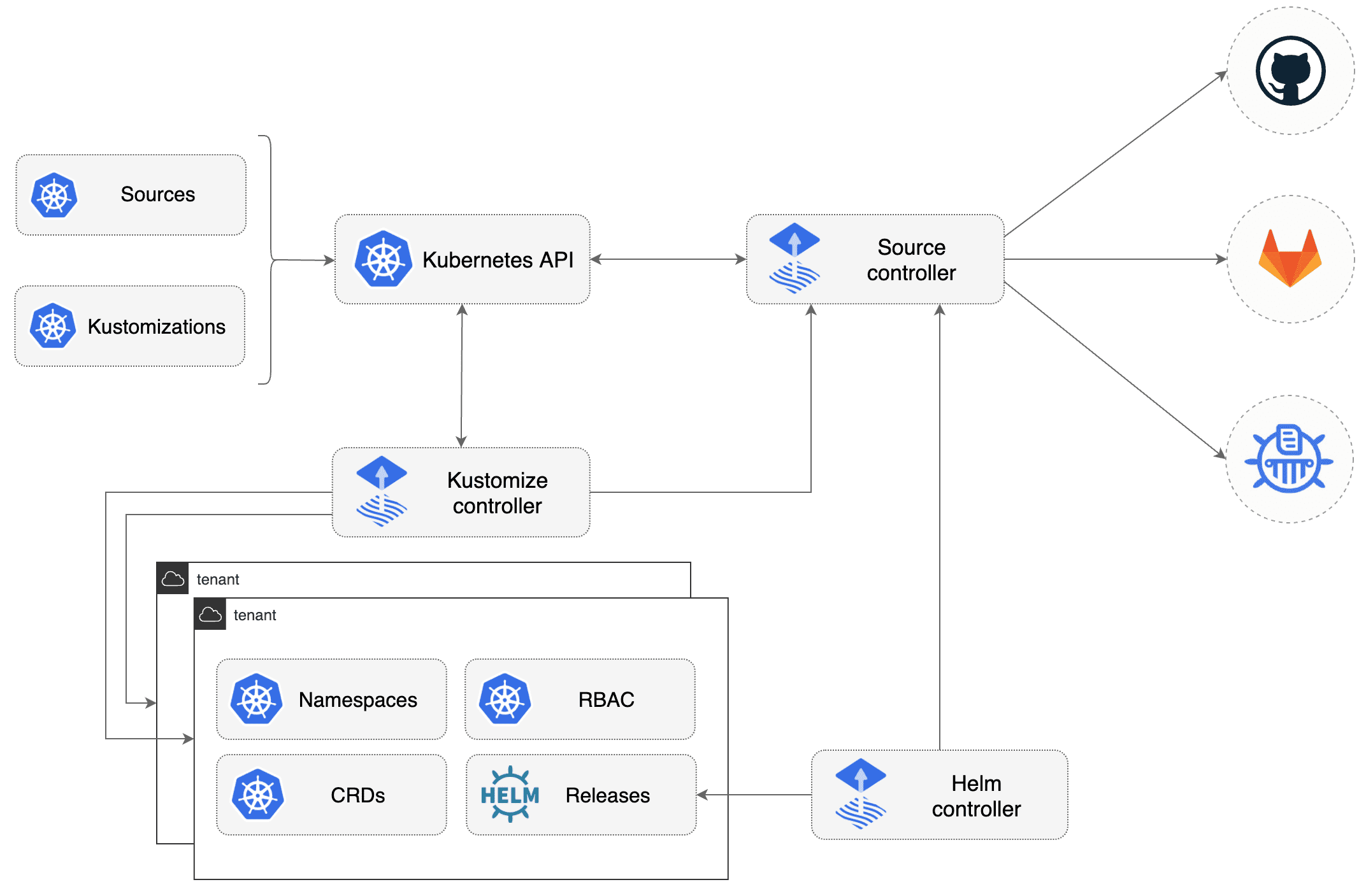
GitOps is a way of managing your infrastructure and applications so that whole system is described declaratively and version controlled (most likely in a Git repository), and having an automated process that ensures that the deployed environment matches the state specified in a repository.
Source源,包括期望状态与获取的途径。
A Source defines the origin of a repository containing the desired state of the system and the requirements to obtain it (e.g. credentials, version selectors).
Reconciliation refers to ensuring that a given state (e.g. application running in the cluster, infrastructure) matches a desired state declaratively defined somewhere (e.g. a Git repository).
// children goroutine funcSubFoo(ctx context.Context) { for { select { case <-ctx.Done(): return case <-dataCh: go LongLogic() case <-finishedCh: fmt.Println("LongLogic finished") } } }
wordpress/ Chart.yaml # A YAML file containing information about the chart LICENSE # OPTIONAL: A plain text file containing the license for the chart README.md # OPTIONAL: A human-readable README file values.yaml # The default configuration values for this chart values.schema.json # OPTIONAL: A JSON Schema for imposing a structure on the values.yaml file charts/ # A directory containing any charts upon which this chart depends. crds/ # Custom Resource Definitions templates/ # A directory of templates that, when combined with values, # will generate valid Kubernetes manifest files. templates/NOTES.txt # OPTIONAL: A plain text file containing short usage notes
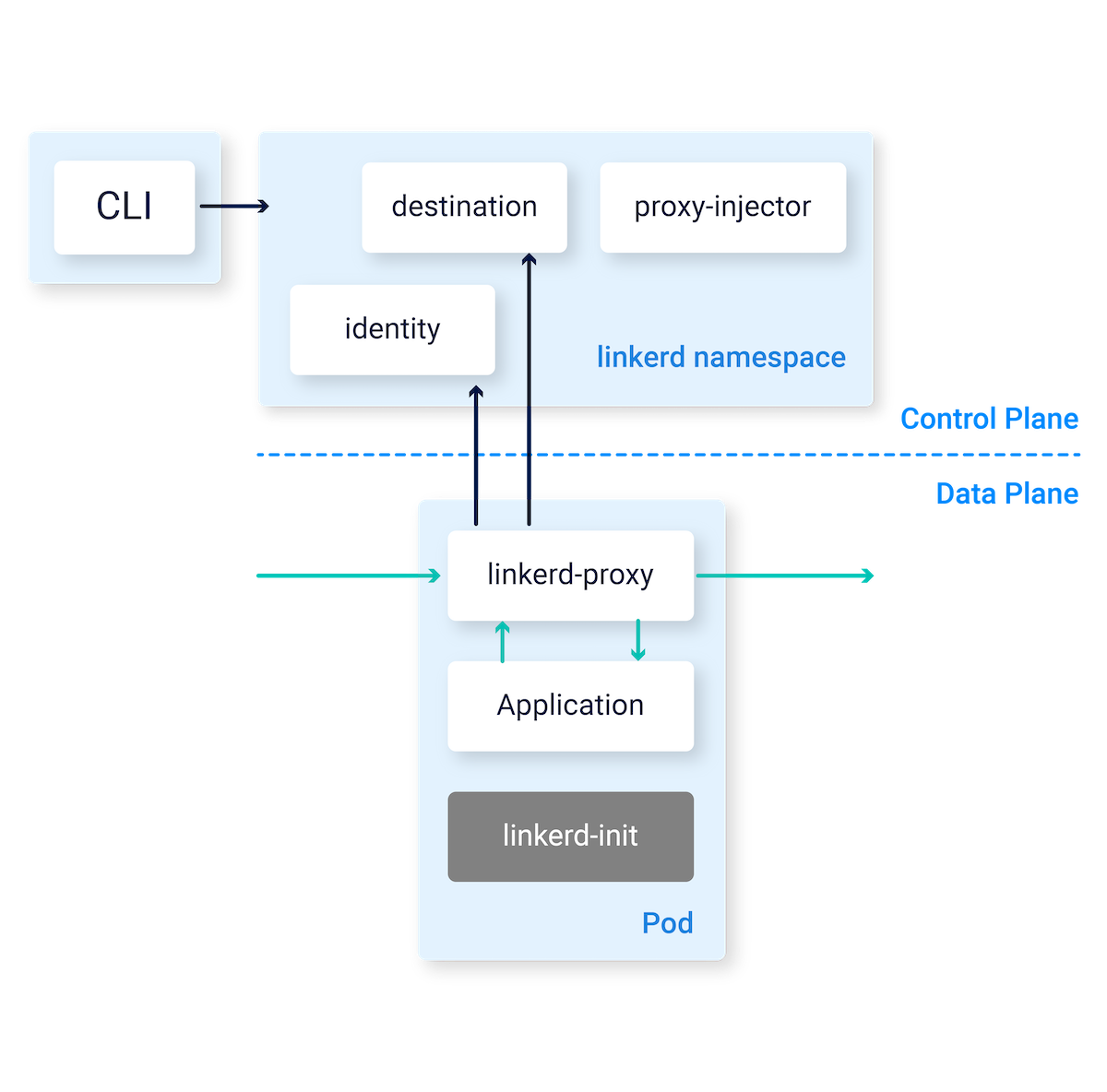
A service mesh like Linkerd is a tools for adding observability, security, and reliability features to “cloud native” applications by transparently inserting this functionality at the platform layer rather than the application layer.
TiKV provides both raw and ACID-compliant transactional key-value API, which is widely used in online serving services, such as the metadata storage system for object storage service, the storage system for recommendation systems, the online feature store, etc.
RawKV’s average response time less than 1 ms (P99=10 ms).
延迟是IO相关的软件很重要的特性。但对于这个特性,我们要注意两点:
只针对简单KV,而不针对事务
真实延迟很依赖存储介质
从这点来看,在TiKV层面引入事务的特性前,需要我们要斟酌一下它对延迟的影响。
High scalabilit
With the Placement Driver and carefully designed Raft groups, TiKV excels in horizontal scalability and can easily scale to 100+ terabytes of data. Scale-out your TiKV cluster to fit the data size growth without any impact on the application.
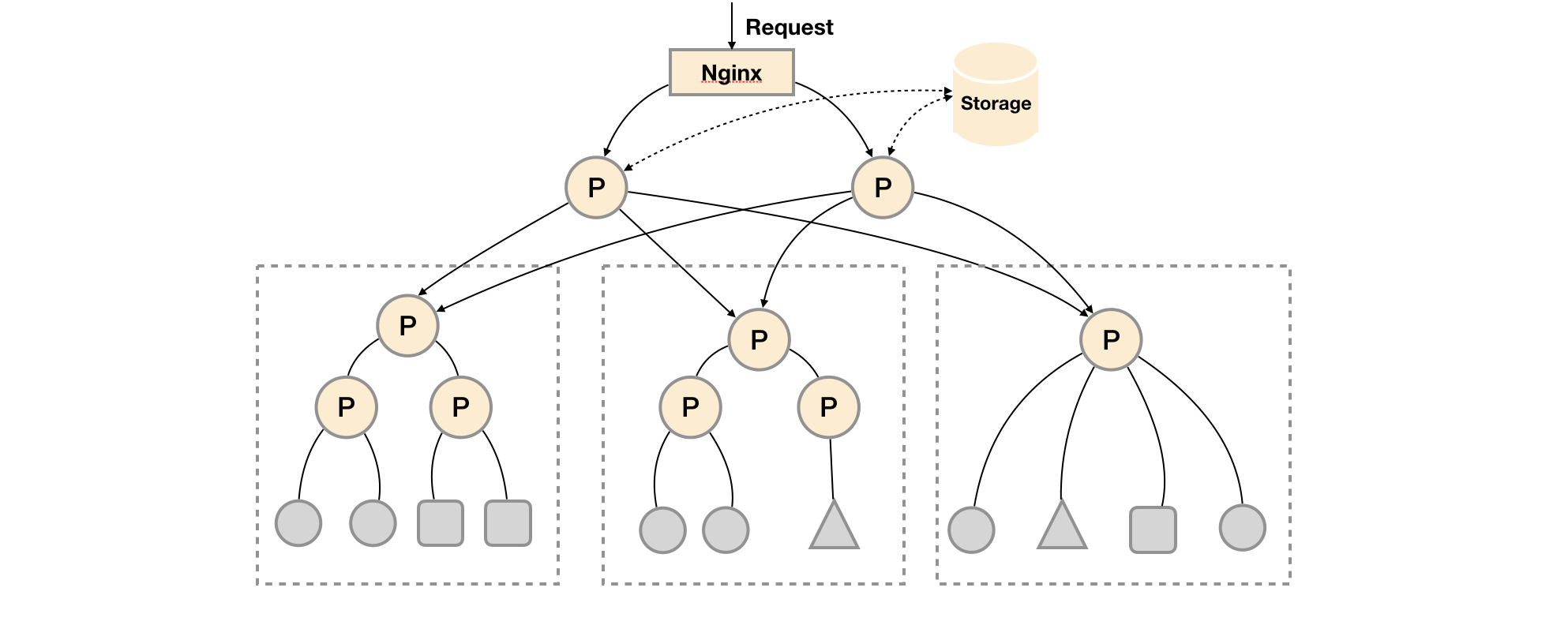
A database clustering system for horizontal scaling of MySQL
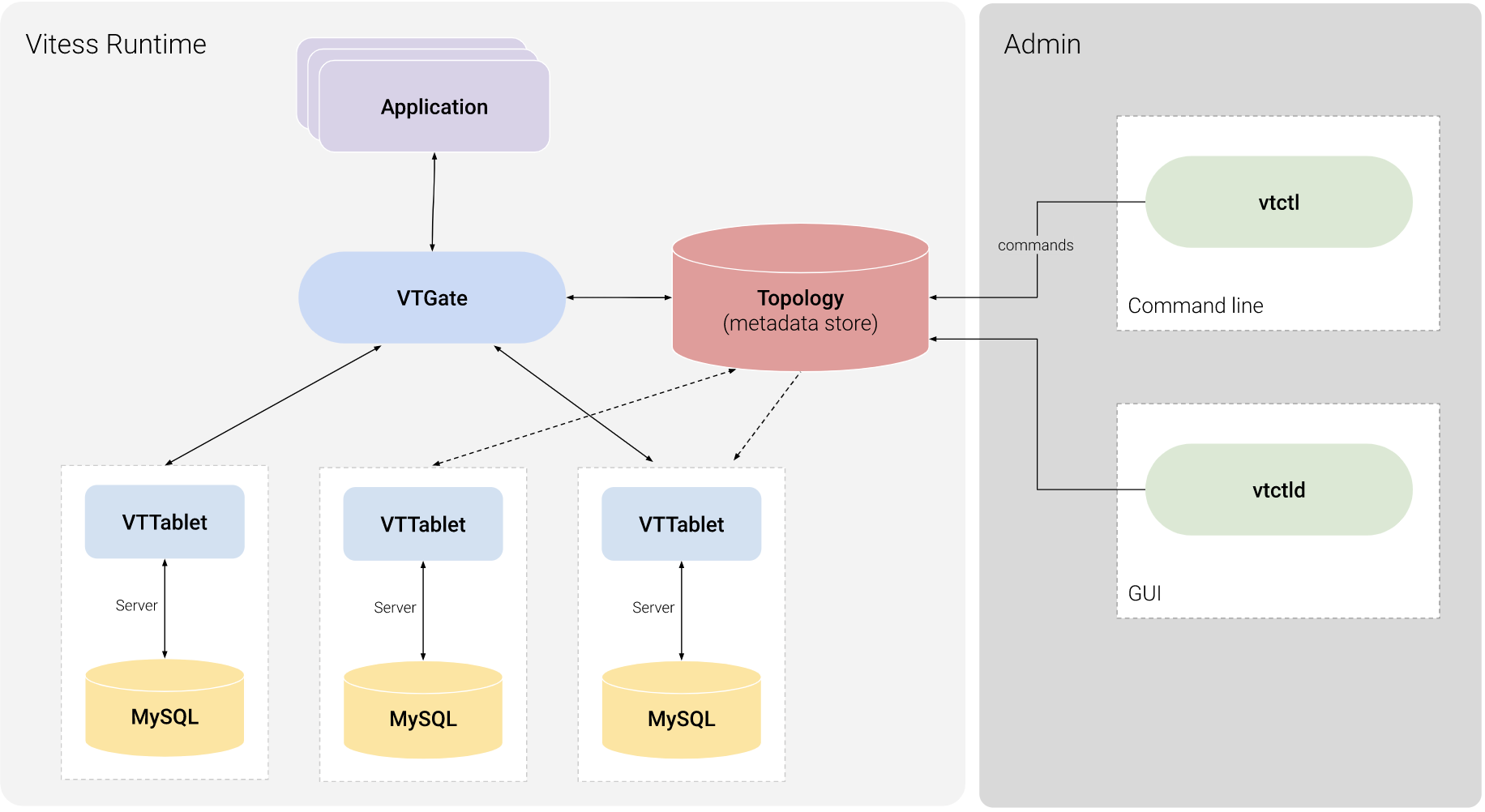
我们直接从架构图入手,来了解它是怎么实现 MySQL横向扩展 的。
我们关注最核心的两个模块:
VTTablet
A tablet is a combination of a mysqld process and a corresponding vttablet process, usually running on the same machine. Each tablet is assigned a tablet type, which specifies what role it currently performs.
VTGate is a lightweight proxy server that routes traffic to the correct VTTablet servers and returns consolidated results back to the client. It speaks both the MySQL Protocol and the Vitess gRPC protocol. Thus, your applications can connect to VTGate as if it is a MySQL Server.