
2022-02-21 自顶向下地写出优雅的Goroutine(下)
通过前面两篇的铺垫,我们对 父子进程的生命周期管理 与 select代码的核心机制 有了基本的了解。
今天我们再接着看看在具体工程中的优化点。注意,在上一篇,我们已经把问题聚焦到了耗时较长的处理函数中。
实时处理
我们先看回顾上一讲的这段代码:
1 | case <-dataCh: |
简单想一下,我们会觉得LongLogic()这里会很容易出现性能问题:当dataCh的数据写入速度很快时,有大量的LongLogic()还未结束、仍在程序内运行,导致CPU超负荷。
但是,如果这些代码编写的逻辑问题确实就是业务逻辑,即:程序确确实实需要实时处理这么多的数据,那我们该怎么做呢?
常规思路中引入 排队机制 确实是一个方案,但很容易破坏原始需求 - 实时计算处理,排队机制会导致延迟,那这就是业务无法接受的。在现实中,扩增资源是最直观的解决方案,最常见是利用Kubernetes平台的Pod水平扩容机制,保证CPU使用率到达一定程度后自动扩容,而不用在程序中加上限制。
这个问题的本质上是实时计算资源的需求。
非实时处理 - 程序外优化
在实际工程中,我们其实往往对实时性要求没有那么高,所以排队等限流机制带来的延时可以接受的。而综合考虑到研发代码质量的不确定性,迭代过程可能中会引入bug导致调用量暴增,这时限流机制能提升程序的健壮性。
在程序外部,我们可以依赖消息队列进行削峰填谷:
- 配置消息积压的告警来保证生产者程序的监控
- 配置限流参数来保证不要超过消费者程序的处理极限
在这里,消费队列在软件架构中是一个 分离生产与消费程序 的设计,有利于两侧程序的健壮性。在计算密集型的场景中,意义尤为重大。
非实时处理 - 程序内优化
上面消息队列方案虽然很棒,但从系统来说引入了一个新的组件,有时一种杀鸡用牛刀的感觉,对部分没有消息队列的团队来说也比较难以接受。
那么,我们尝试在程序中做一下优化。首先,我们在上层要做一次抽象,将逻辑收敛到一个独立的package中(示例中为logic),方便后续优化
1 | func SubFoo(ctx context.Context) { |
而logic包中的大致框架如下:
1 | package logic |
我们也可以在这里加一个error返回,在排队满时返回给调用方,由调用方决定怎么处理,如丢弃或重新排队等。排队机制的代码是业务场景决定的,我就不具体写了,本质上类似于一个线程池管理。
小结
从今天,我们分别从三个场景分析了耗时较长的处理函数:
- 实时处理 - 结合Paas平台进行资源扩容
- 非实时处理 - 程序外优化 - 引入消息队列
- 非实时处理 - 程序内优化 - 程序内的线程池
到这里,我们自顶向下地写出优雅的Goroutine的三讲已经完成了,希望对大家有所启发,也欢迎向我提问。
2022-02-22 CNCF-Prometheus
看完了调度管理层与应用层的项目后,我们接下来了解可观察性和分析这块。提升可观察性和分析能力,非常有助于对整套系统的掌控。
今天的主角是CNCF中第二个毕业的项目 - Prometheus,它提供了软件系统核心的监控功能。我们今天就从核心架构入手,了解其特性。
架构
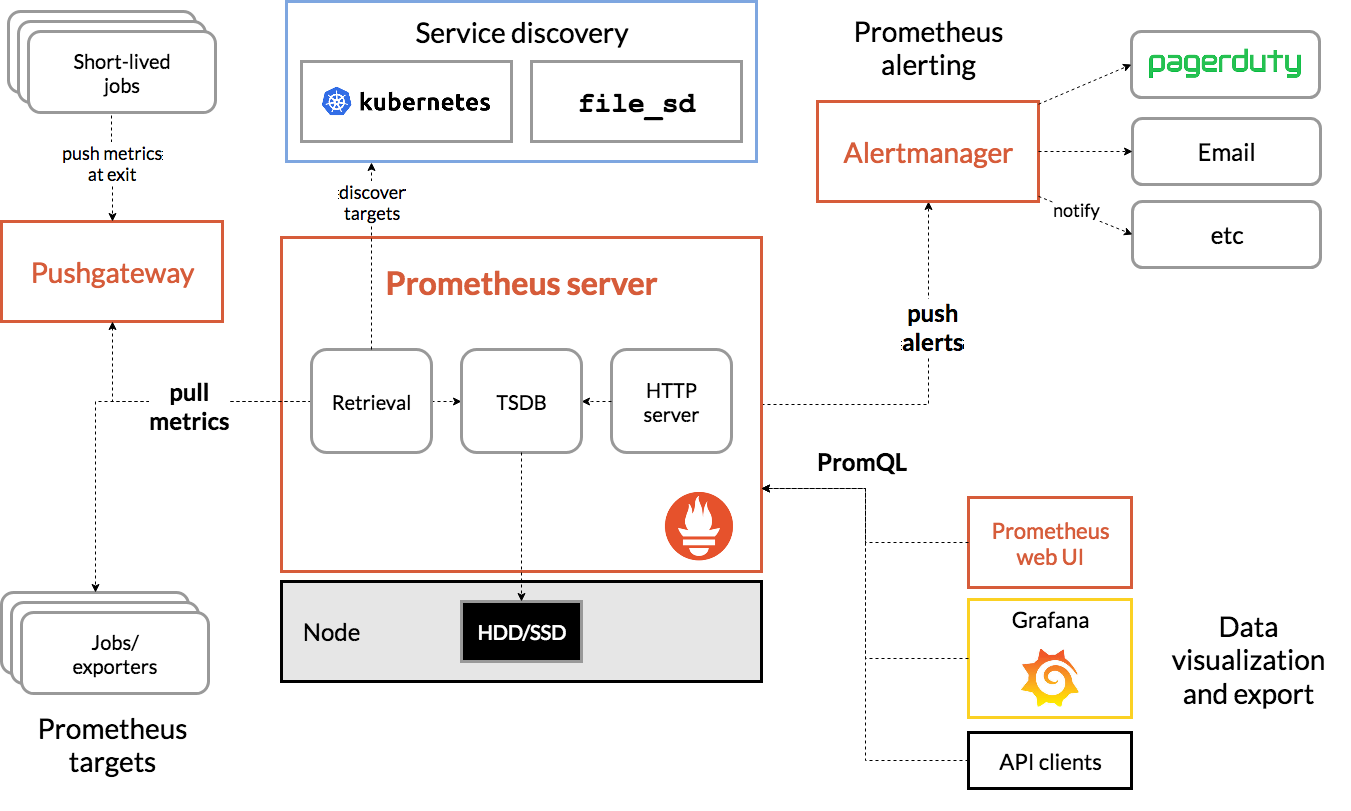
这张图中的内容核心分为五块:
- 指标收集端 - Exporters + Pushgateway
- Exporters 长生命周期的进程,将指标保存在内存,重启后清零
- Pushgateway 作为短生命周期指标的“中转站”
- 服务端 - Prometheus Server
- 服务发现 - Kubernetes等
- 对接Kubernetes平台原生兼容
- 对接非k8s平台,可以选择consul或者直接采用静态文件配置
- 告警 - Alertmanager
- 展示 - Prometheus web UI + Grafana等
- web ui可以用来查看简单的指标
- Grafana是最主流的指标展示工具,没有之一
文档写得比较粗糙,欢迎大家通过这个视频链接看看更详细的说明 https://www.bilibili.com/video/BV1PP4y1c7ps/
八大特性
- 多维度数据Dimensional data - Prometheus implements a highly dimensional data model. Time series are identified by a metric name and a set of key-value pairs.
- 强力的查询Powerful queries - PromQL allows slicing and dicing of collected time series data in order to generate ad-hoc graphs, tables, and alerts.
- 很棒的可视化Great visualization - Prometheus has multiple modes for visualizing data: a built-in expression browser, Grafana integration, and a console template language.
- 高效存储Efficient storage - Prometheus stores time series in memory and on local disk in an efficient custom format. Scaling is achieved by functional sharding and federation.
- 简单操作Simple operation - Each server is independent for reliability, relying only on local storage. Written in Go, all binaries are statically linked and easy to deploy.
- 精确告警Precise alerting - Alerts are defined based on Prometheus’s flexible PromQL and maintain dimensional information. An alertmanager handles notifications and silencing.
- 很多客户端库Many client libraries - Client libraries allow easy instrumentation of services. Over ten languages are supported already and custom libraries are easy to implement.
- 大量现有集成Many integrations - Existing exporters allow bridging of third-party data into Prometheus. Examples: system statistics, as well as Docker, HAProxy, StatsD, and JMX metrics.
小结
Prometheus的官方文档 - https://prometheus.io/docs/introduction/overview/ 提供了很多有价值的信息,尤其是原理和最佳实践。我也曾经实践过一套企业级的Prometheus平台,有机会的话会和大家分享分享。
2022-02-23 CNCF-Cortex/Thanos
今天,我将串讲两个基于Prometheus的扩展的项目:Cortex和Thanos。
为了让大家更好地了解到大型监控系统的方案,我将结合Prometheus自带的联邦方案和大家聊聊。
Prometheus的联邦模式
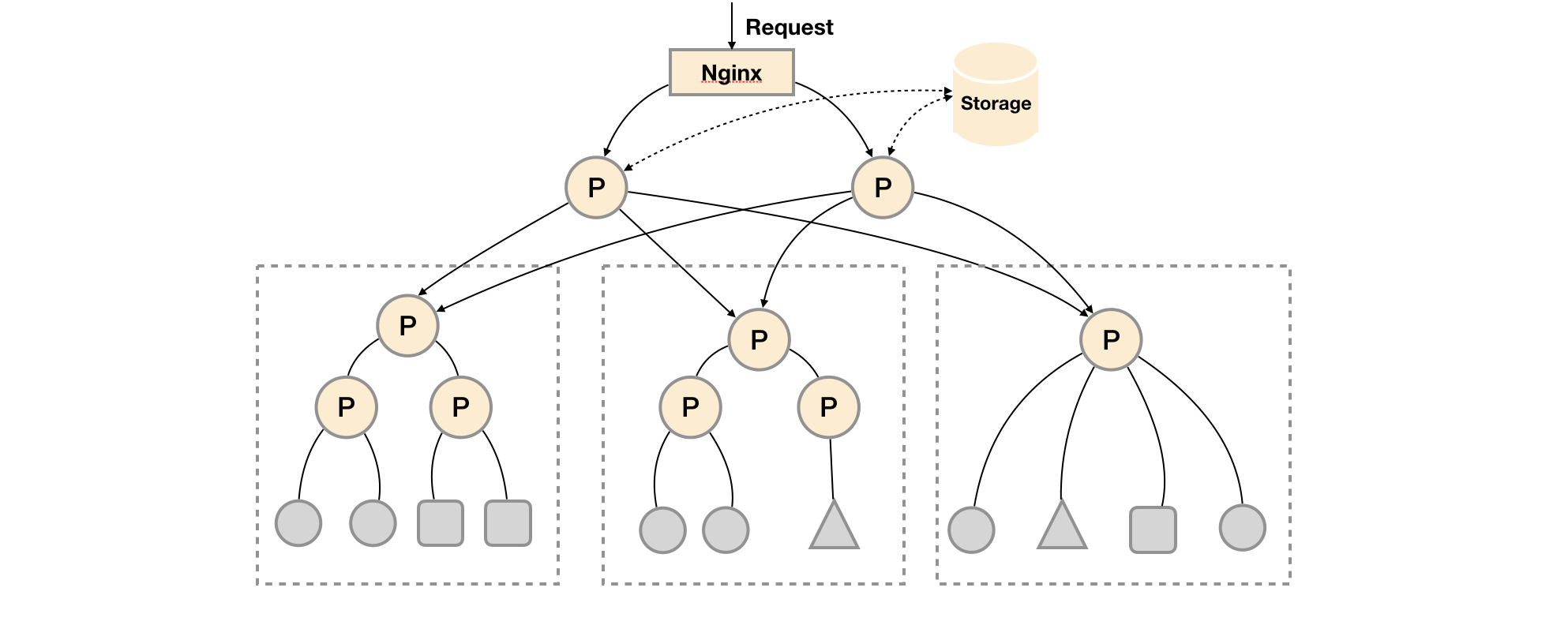
联邦模式是一种树状的级联模式,核心体现出了一个点:Prometheus本身就是一种Exporter,可以用来采集指标。
关于这个架构,我们还能发现以下特点:
- Prometheus高可用方案,是多个上层节点重复Pull下层数据,本质上仍然是单点保存全量数据
- Prometheus提供远程存储方案,但远程存储的能力很有限,往往只能支持异常后数据恢复
- Prometheus提供了record rule等指标加工能力,可以减少上层的数据存储
- 可以更好地保证网络的安全性,减少防火墙的配置
联邦模式基本能支持大多数Prometheus的场景,一般建议优先考虑。
Cortex
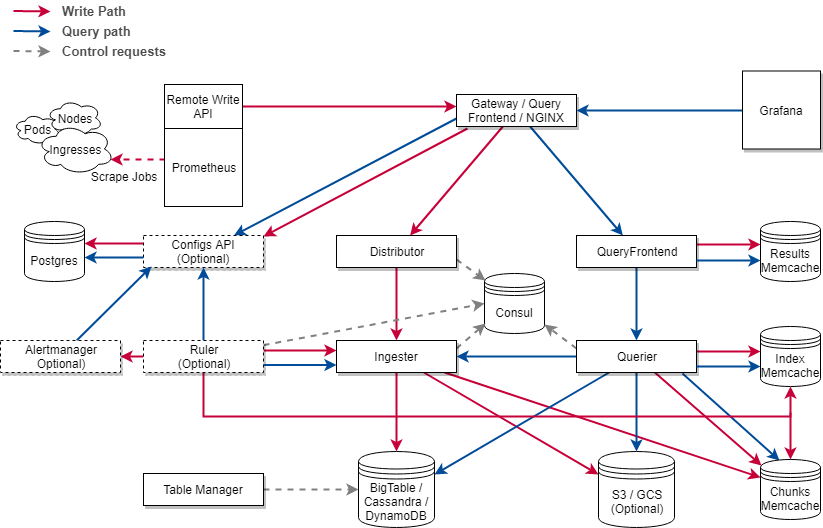
对标到上面的Prometheus联邦模式,Cortex核心是依赖远程写的接口。写完数据后,Cortex就与Prometheus完全没有依赖了。也就是说,Cortex是构建在Prometheus之上的一套解决方案。
上面的架构有很多细节上的实现,但我不想在这里聊得太细,主要考虑到:作为使用方,我们不需要过于关注Cortex的实现,毕竟它只依赖Prometheus远程写的接口,完全可以独立于Prometheus、快速迭代自身的架构。
所以,如果你想使用Cortex,可以看看官方的介绍文档 - https://cortexmetrics.io/,有什么特性是你特别关注的。
Thanos
Thanos提供了两种模式Sidecar和Receive,其中后者提出的时间不长,与Cortex的实现基本一致,我们就不细看了。我们重点看看边车的实现。
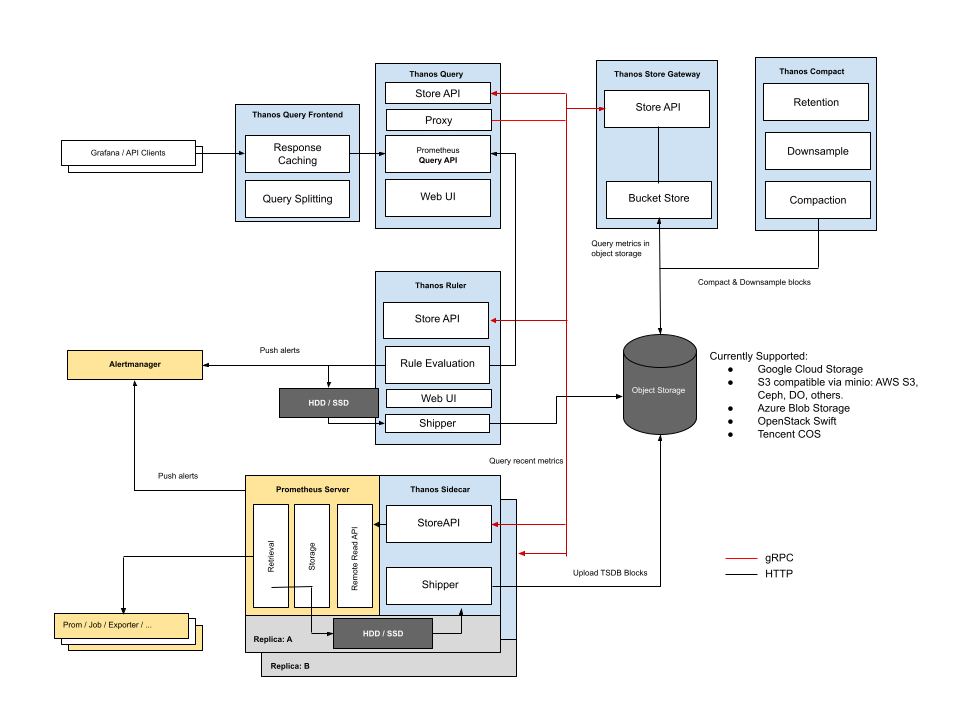
我们重点聚焦到Thanos和Prometheus的交互:
- 读 - 从Thanos传到Prometheus远程读的接口,再进行数据查询
- 写 - 由于是sidecar模式,两者共享Pod里的数据,所以Prometheus写入的数据可以由Thanos直接访问
从这两点来看,Thanos好像什么都没做,那它的意义在哪呢?其实,Thanos的核心是:依赖图中的对象存储,实现出的一套分布式的解决方案。
我们上文提到,Prometheus本质上还是一个单体的架构,而Thanos提供的分布式方案,从理论上可以解决单点计算力的问题。所以,Thanos对标Prometheus和Cortex的差异性价值,非常依赖它在分布式上的表现。
小结
整体来说,关于Prometheus的扩展方案,我个人的倾向如下:
- 联邦模式:使用Prometheus的必要基础,有很多优化技巧,建议优先考虑;
- Cortex:对现有的Prometheus侵入小,适合快速解决问题,但长期来看很受限;
- Thanos:是对Prometheus从单体到分布式的一种改造,发展前景很棒,但遇到的问题也自然更多;
今天聊的这三种方案理解起来不难,我更希望对大家在软件架构上有所启发。
Github: https://github.com/Junedayday/code_reading
Blog: http://junes.tech/
Bilibili: https://space.bilibili.com/293775192
公众号: golangcoding
