
2022-02-28 CNCF-OpenTelemetry等
今天,我们会以OpenTelemetry的三个核心Metrics、Logs、Traces为切入点,来看看OpenMetrics、Fluentd、Jaeger这三个具有代表性的项目。
OpenTelemetry
OpenTelemetry主要分为三大块:Metrics、Logs、Traces。
- Metrics指标:程序将运行中关键的一些指标数据保存下来,常通过RPC的方式Pull/Push到统一的平台
- Logs日志:依赖程序自身的打印。可通过ELK/EFK等工具采集到统一的平台并展示
- Traces分布式追踪:遵循Dapper等协议,获取一个请求在整个系统中的调用链路
OpenTelemetry有多语言的、具体落地的现成库,供业务方快速落地实践。
更多可以参考 https://junedayday.github.io/2021/10/14/readings/go-digest-2/
Metrics - OpenMetrics
Evolving the Prometheus exposition format into a standard.
这个项目更多的是一种规范性质,基本就是以Prometheus的指标为标准。
更多的信息可以参考 https://prometheus.io/docs/instrumenting/exposition_formats/。
Logs - Fluentd
unified logging layer 统一的日志层
我们这里谈的Logs并不是指各编程语言的日志库,更多是指对日志产生后,如何进行解析与采集,而Fluentd就是一个代表性的项目。
当前主流的日志采集与分析方案,也由ELK转变成了EFK,也就是Logstash被Fluentd所替代。
Fluentd最核心的优势,在于它提供了大量的可供快速接入的插件 - https://www.fluentd.org/plugins。
Traces - Jaeger
open source, end-to-end distributed tracing
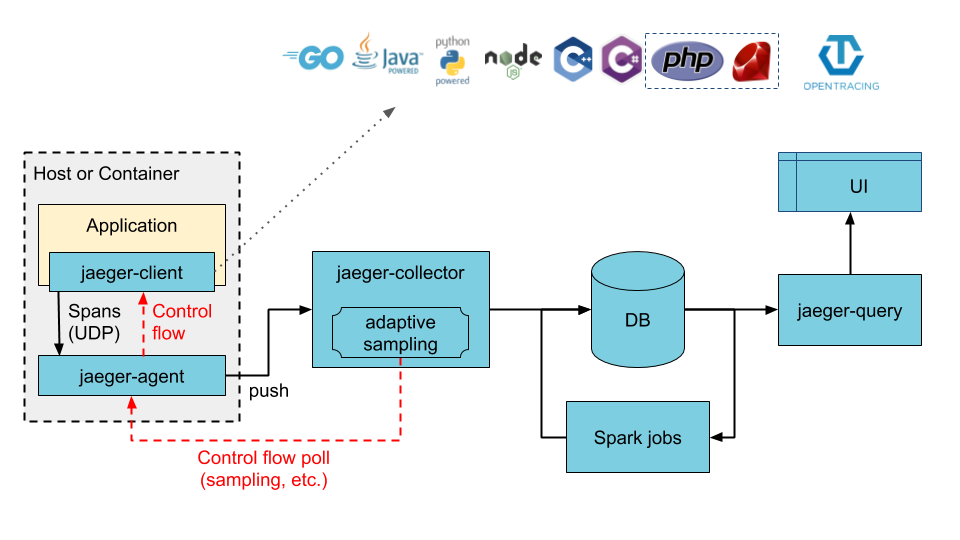
Jaeger为OpenTracing提供了一套具体落地的方案,在Jaeger-Client侧也提供了多语言的SDK,我们就可以在分布式系统中查到请求的整个生命周期的具体数据。但落地到平台时,我们要重点思考以下两点:
- Traces与Logs的关联:两者的收集、推送、分析、展示的整个链路非常相似,而且我们也往往希望在Trace里查询信息时,能查到应用程序中自行打印的日志;
- Traces与Service Mesh的关联:Jaeger-Agent与Service Mesh的Sidecar模式非常类似,两者该怎么配合实践
我们可以独立建设Traces、Logs、Service Mesh这三块技术,但如果能将它们有机结合起来,有助于整个基础平台的统一化。
小结
OpenTelemetry提倡的可观测性在复杂工程中非常重要,能大幅提高程序的可维护性。如果有机会实践,建议大家应优先理解它的理念,再结合当前开源生态进行落地。
2022-03-01 CNCF-Litmus/ChaosMesh
随着Kubernetes的落地,混沌工程在近几年越来越流行,CNCF也将它作为重点项目。如果用一个词概括混沌工程,最常用的就是 故障注入。
今天我将针对其中两个重要项目 - Litmus 和 ChaosMesh 做简单介绍,让大家对混沌工程有基本理解。
Litmus
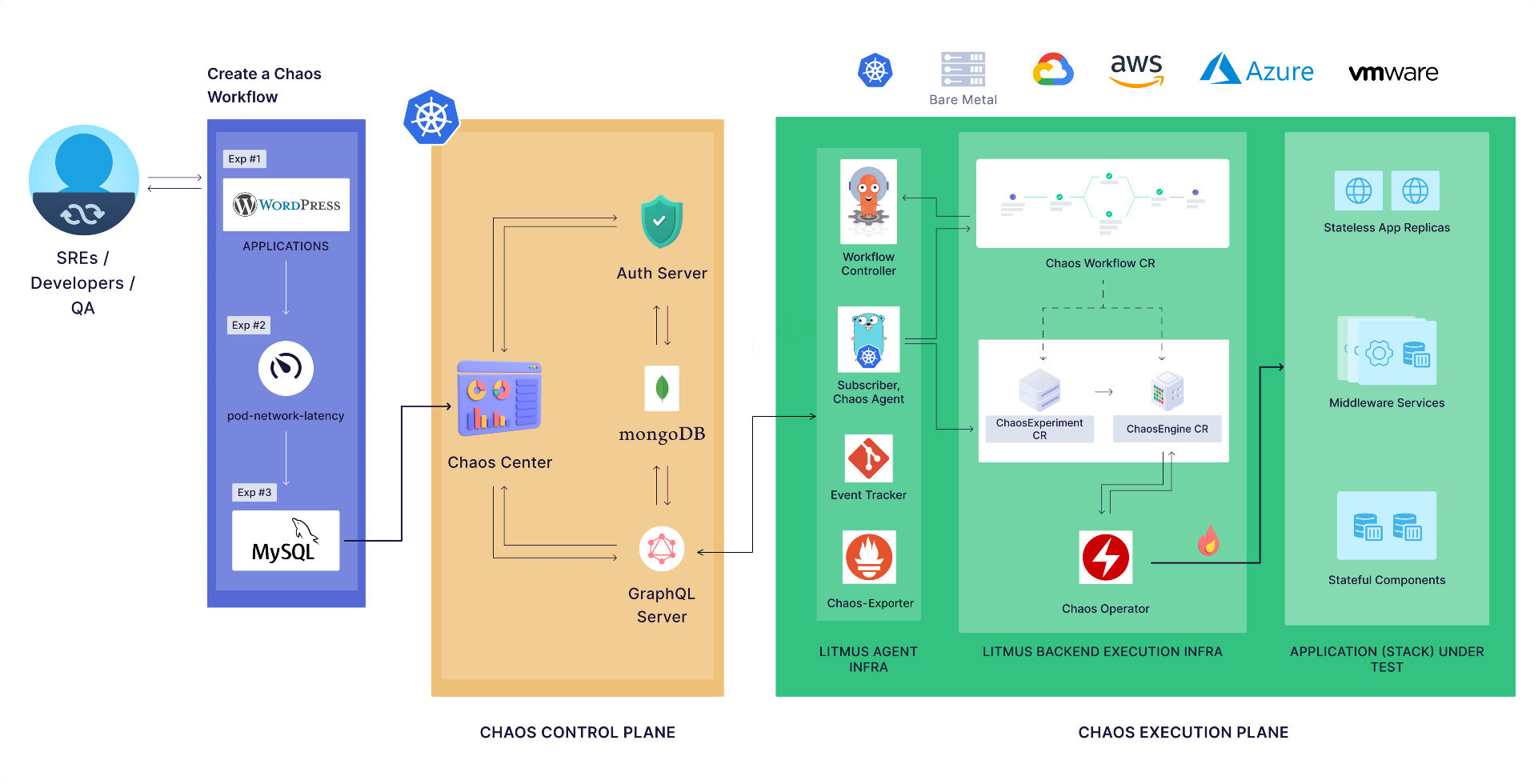
Litmus的架构分为控制平面和执行平面。前者更多是提供可交互的web界面与整体的功能管理;而后者更专注于具体故障功能的实现。
整体来说,Litmus的架构是比较重量级的:
- 平台组件复杂
- 和Argo/Prometheus等软件有一定的交叉
ChaosMesh
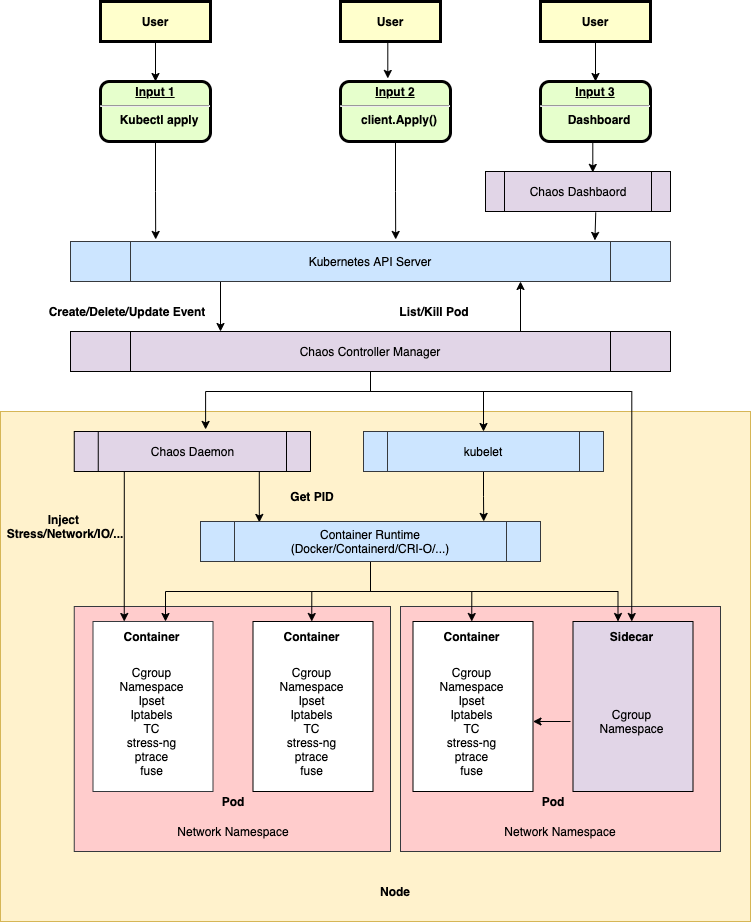
相对而言,Chaos Mesh是一个比较轻量级的实现,整体的架构分为三块:
- Dashboard - 提供界面化交互能力
- Controller Manager - 统一管理多种CRD
- Daemon - 负责Pod端具体的故障注入
我们可以仔细分析这里的三大块,都有不少的扩展点:
- 可通过kubectl或自定义客户端下发指令
- Controller Manager 可实现工作流等复杂CRD
- Daemon可通过直接请求、容器运行时和Sidecar三种方式注入错误
故障注入能力
我个人更看好ChaosMesh这个项目,它的架构图中所呈现的扩展性非常棒。那么,接下来我就以Chaos Mesh为例,看看它所提供的的故障注入能力:
- 基本故障:
- PodChaos: Pod
- NetworkChaos: 网络
- DNSChaos: DNS
- HTTPChaos: HTTP
- StressChaos: CPU或内存
- IOChaos: IO
- TimeChaos: 时间
- KernelChaos: 内核
- 平台故障:
- 应用故障:
- JVMChaos: JVM
要覆盖基本故障这些case,已经需要投入非常多的人力物力了。
小结
我个人认为,混沌工程更多地是面向Iaas/Paas/Saas这类通用服务而提供的能力:
- Iaas/Paas/Saas这类服务是大规模共用的,对稳定性要求极高,才能体现出混沌工程的价值;
- 在业务系统中引入混沌工程有两大问题:
- 一方面,ROI是非常低的,业务变化多、迭代快,从业务开发的角度来看,更希望基础平台侧能覆盖这些异常情况
- 另一方面,混沌工程会带来很多不确定性,可能导致业务受损
对大部分的开发者来说,可以学习混沌工程的理念,提高自己设计系统时的健壮性,但不要过于追求完美。
2022-03-02 CNCF-Rook/Longhorn
今天,我们一起看看CNCF中存储这块。在云原生的环境下,分布式存储绝对是排名前三的技术难点,我也不可能通过短短五分钟描述清楚。
所以,我将针对性地介绍核心概念,帮助大家有个初步印象。
CSI - Container Storage Interface
容器存储之所以能在市场中蓬勃发展,离不开一个优秀的接口定义 - CSI。有了标准可依,各家百花齐放、优胜劣汰。
CSI规范链接 - https://github.com/container-storage-interface/spec/blob/master/spec.md
CSI整套规范内容很多,非存储这块的专业人士无需深入研究。不过,我们可以将它作为一个学习资料,花10分钟看看如下内容:
- 记住核心术语概念 - https://github.com/container-storage-interface/spec/blob/master/spec.md#terminology
- 了解架构 - https://github.com/container-storage-interface/spec/blob/master/spec.md#architecture
- 学习核心RPC的命名 - https://github.com/container-storage-interface/spec/blob/master/spec.md#rpc-interface
Ceph
开源中最有名的分布式存储系统当属Ceph了。它并没有被捐献给CNCF组织,所以我们无法在全景图里找到它。
这里不会讨论Ceph的细节,但还是希望大家能够了解:Ceph的维护成本不低,不要把它当作分布式存储的“银弹”。
所以,对于中小型公司来说,核心业务优先考虑使用公有云的存储产品。
Rook
Rook这个项目其实分为两类概念:
- 云原生存储编排引擎 - Rook
- 对接具体文件系统的实现 - rook-ceph/rook-nfs
Rook将Ceph的存储抽象为了Kubernetes系统中的Pod,进行统一调度,更加贴合云原生的设计理念。
Rook在市场上的应用基本集中在rook-ceph上,不太建议使用rook-nfs。
Longhorn
CNCF中另一个项目 - Longhorn则选择脱离Ceph的生态,实现了一整个从编排到具体存储的链路。
从其官方介绍来说,它更聚焦于微服务的场景,也就是能调度更大量级的Volume。
关于Longhorn的实践资料并不多,很难对其下结论,不过官方提供了完善的文档资料,给对应的开发者不小信心。
官网 - https://longhorn.io/
小结
分布式存储是一块仍在快速发展的领域,对大部分公司或团队来说选择比较有限:
- 优先考虑云服务
- 有Ceph维护经验+一定二次开发能力的,考虑rook+ceph
- 有强烈的技术信心的,可以考虑小规模落地Longhorn体验
到这里,我再补充一点:我们千万不要过度迷恋分布式存储中的“分布式”这个词,很多时候单点存储(本地存储和远程存储)就能满足我们的开发要求了。
2022-03-03 CNCF-containerd/cri-o
容器的运行时是Kubernetes运行容器的基础。与CSI类似,Kubernetes提出了CRI - Container Runtime Interface的概念。
今天,我们会更多地关注到CRI这个规范,而不会对这两个项目底层进行分析 - 毕竟,虽然提供了开放的接口,但目前绝大部分的k8s依然是以Docker容器作为具体实现的,并且这现象会持续相当一段时间。
我会侧重讲讲它们之间的联系。
CRI
CRI主要是针对的是Kubernetes中kubelet这个组件的,它用于在各个Node节点管理满足标准的OCI容器。
OCI是一个容器界的事实标准,主流的容器都满足该规范,我们在这里了解即可。
CRI最新的版本可以参考这个链接 - https://github.com/kubernetes/cri-api/blob/release-1.23/pkg/apis/runtime/v1alpha2/api.proto
CRI主要分为如下:
- RuntimeService 运行时服务
- PodSandbox 相关,即Pod中的根容器,一般也叫做pause容器;
- Container 相关,即普通的容器;
- ImageService 镜像服务
CRI里的内容很多,我这边分享个人阅读大型protobuffer文件的两个技巧:
- 弄懂高频词汇,如上面的Sandbox
- 聚焦核心的枚举enum
这里有两个枚举值得关注:
1 | enum PodSandboxState { |
看到这两个定义,如果你对容器/Pod有一定的了解,能很快地联系到它们的生命周期管理了。
containerd
我们看看Docker与Kubernetes的分层:
Docker Engine -> containerd -> runc
Kubernetes(Kubelet组件) -> containerd -> runc
所以,containerd的作用很直观:对上层(Docker Engine/Kubernetes)屏蔽下层(runc等)的实现细节。
cri-o
LIGHTWEIGHT CONTAINER RUNTIME FOR KUBERNETES
从定义不难看出,它是面向Kubernetes的、更为轻量级的CRI。cri-o属于我们前面聊过的OCI项目之一。
对应上面的分层,cri-o封装的是runc这种具体的实现,让上层(Kubernetes)不需要关心下层具体运行容器的引擎。
小结
今天涉及的概念有很多,其实问题起源是 Docker没有捐献给CNCF基金会,为了摆脱不确定性,Kubernetes想解耦Docker这个强依赖。
无论是抽象出标准接口,还是通过分层设计,从理论上的确可以脱离了对Docker的依赖,但现实情况依旧有相当一段路要走,毕竟Docker的存量市场实在太过庞大。
2022-03-04 CNCF-CNI/Cilium
之前我们了解了CSI和CRI这两大块,今天我们将接触到Kubernetes另一个重要规范 - CNI,也就是Container Network Interface。
了解分布式系统的同学都深有体会,网络绝对是最复杂的因素,无论是拥塞、延迟、丢包等常规情况,还是像网络分区等复杂难题,都需要大量的学习成本。无疑,CNI的学习难度也是非常高的。而Cilium作为CNI的一种实现,我今天依然会简单带过。
CNI规范
解决什么问题
CNI没有像CSI/CRI那样有一个明确的接口定义。要想了解它,我们先要理解它要解决的问题。
简单来说,就是在Kubernetes的容器环境里, 分配容器网络并保证互相联通。
核心五个规范
- A format for administrators to define network configuration. 网络配置的格式
- A protocol for container runtimes to make requests to network plugins. 执行协议
- A procedure for executing plugins based on a supplied configuration. 基于网络配置的执行过程
- A procedure for plugins to delegate functionality to other plugins. 插件授权
- Data types for plugins to return their results to the runtime. 返回的格式
CNI插件
我们通常谈到CNI的插件,会存在歧义,主要有两种理解:
- 一种是涉及到CNI底层开发的插件,可参考 https://www.cni.dev/plugins/current/ , 主要为自研提供基础能力;
- 另一种是已经实现CNI的现有项目,如 Flannel、Calico、Canal 和 Weave 等
CNI项目对比
CNI的可选项目有很多,如市场上主流的Flannel和Calico,CNCF中的Cilium等。
对于绝大多数的用户,我们不会关心具体实现,更多地是希望找到一个最适合自己的。横向对比的网络资料有很多,我这里提供一张图作为参考。
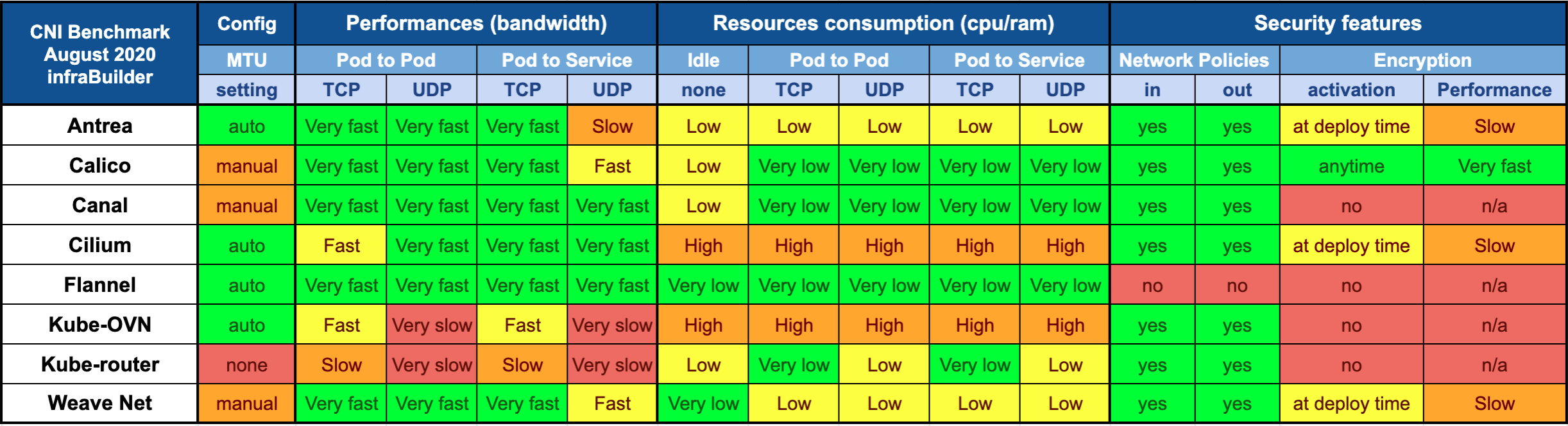
这里面的对比维度会让我们在选型时有所启发:
- 配置
- 性能(带宽)
- 资源消耗
- 安全特性
注意,表格里的快与慢、高与低都是相对值,在Kubernetes集群规模较大时才有明显差异。
小结
在落地Kubernetes时,我们不要盲目地追求速度快、性能高的方案,尤其是对规模小、没有资深运维经验的团队,应该优先实现最简单、最容易维护的方案。
基于CNI的容器网络解决方案,替换性会比较强,可以在后续有了足够的经验、遇到了相关的瓶颈后,再考虑针对性地迁移。
Github: https://github.com/Junedayday/code_reading
Blog: http://junes.tech/
Bilibili: https://space.bilibili.com/293775192
公众号: golangcoding
