
2022-02-07 CNCF-CloudEvents
今天,我们一起来看CloudEvents,并不是一款成熟的软件系统,而更像是一种协议与标准。不过,它提出的相关概念,对我们开发与设计软件系统时,很有参考意义。
- 官网 - https://cloudevents.io/
- Github - https://github.com/cloudevents/spec
官方定义
CloudEvents is a vendor-neutral specification for defining the format of event data.
顾名思义,CloudEvents项目旨在定义 云时代的事件。事件是一个很广的定义,在不同的软件系统里有不同的表现形式。
想要将所有软件系统里的事件进行标准化,这里面的工作量与难度可想而知,在很长一段时间内很难落地。在我看来,这个项目的意义是长期的 - 先提供一套切实可行的标准与SDK,再尝试结合云原生生态的在核心项目中落地,最后再大规模推广。
核心概念
事件里涉及到了很多概念,我选择其中的核心概念,并将其分成了两类。
完整的内容可以参考: https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#notations-and-terminology
数据类:
- Occurrence - 发生(客观事实)
- Data - 数据
- Context - 上下文
- Event - 事件
传输类:
- Producer - 生产者
- Intermediary - 中介
- Consumer - 消费者
- Event Format - 事件格式
- Message - 消息
- Protocol - 协议
关键字段
CloudEvents给出了规范的同时,也给出了多语言的SDK。我们可以参考它的命名方式,引入到自己的开发系统中。
必填字段:
- id - string
- source - URI-reference
- specversion - string
- type - string
保证 id+source 全局唯一
可选字段:
- datacontenttype - string
- dataschema - string
- subject -string
- time - timestamp,推荐RFC-3339
小结
CloudEvents 目前仍处于非常早期的阶段,有兴趣的朋友,可以尝试引入其SDK,将内部的RPC、MQ等通信数据统一起来。
从长期来看,将一个系统中的事件格式统一起来,对整个系统的帮助是很大的。比如说,我们完全可以将服务注册、服务发现等功能认为是一种事件,要求Etcd、Zookeeper、Consul等均支持该方式,就能有利于相关功能的标准化。
2022-02-08 CNCF-NATS
作为CNCF中消息系统的核心项目,NATS受到了各大公司的青睐,近年来使用量也在逐步提升。有不少同学对消息系统的认识还比较模糊,今天我们就借NATS的核心模型,对消息系统有进一步的认识。
官网 - https://nats.io/
Github - https://github.com/nats-io/nats-server
三种消息传递模型
发布-订阅模式:类似于广播模式
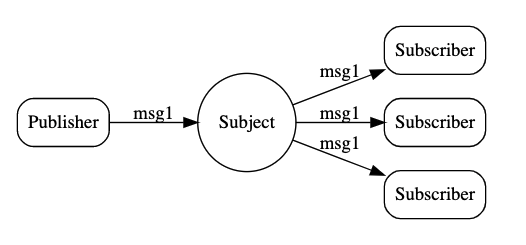
请求-响应模式:对应关系可自行调整,请求者必须等待到响应才认为是成功
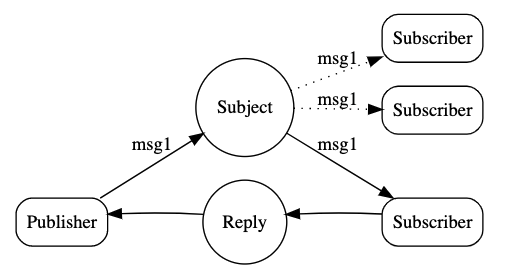
队列-订阅模式:分布式系统中非常重要的消息队列功能,实现消息分发
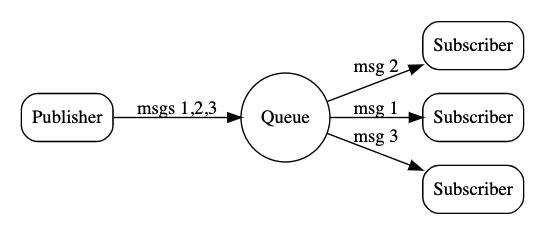
分布式系统中的消息系统
了解上面三种消息传递模型后,你可能仍不清楚它们的适用场景。我建议大家深入地了解这三种模型的本质,这样更方便记忆与理解。其实,在分布式系统中,最核心的是 队列-订阅 模式,其余两种模式意义并不大。
- 发布订阅 只是 队列订阅 的一种特殊的广播模式;
- 请求响应 更多地应结合服务发现能力,在RPC框架中进行实现;
第一点的使用场景不多见,举个例子:
服务2有多个实例,本地内存里保存了一些信息;现在服务1要更新所有服务2中内存的信息,就需要采用发布-订阅模式,否则会导致服务间数据不一致。
如果服务2引入了分布式缓存,那就是队列-订阅模式。
那么,队列-订阅模式 对分布式系统来说有什么意义呢?这其实就是消息队列的价值,我这里列举最关键的两点:
- 削峰填谷:针对分布式系统中的性能问题,通过队列的形式,将高峰期的msg积压到Queue中,在低峰期时交给消费者处理。
- 解耦强依赖:从调用关系可以看到,其实Publisher是要将信息传递给Subscriber;但增加了Queue后,Publisher只与Queue交互,Subscriber也只与Queue交互。可以想象,即便Subscriber短暂地挂了,重启后依旧可以正常使用。
分布式的消息队列还有很多注意点,这里我就不一一列举了,更多的资料大家可以自行搜索。
小结
虽然从生产环境的应用范围来看,NATS仍与老牌的重量级消息队列Kafka有相当大的差距,尤其是在大数据的系统中。但对比RocketMQ、RabbitMQ等轻量级产品,NATS的优势已经越来越明显,尤其是在性能与多语言的SDK上,建议有条件的朋友可以尝试使用。
2022-02-09 CNCF-Helm
Helm在整个云原生平台中扮演了重要角色。值得注意的是,Helm自身的复杂度并不高,它更多依赖的是优秀的设计理念与当前包含大量软件的生态。
官方的定义很简洁,即Kubernetes中的包管理者,即一个公共的软件仓。
The Kubernetes Package Manager
- 官网 - https://helm.sh/
- Github - https://github.com/helm/helm
- 仓库 - https://artifacthub.io/packages
使用Helm
类似于Dockerhub,Helm的一大特色就是使用起来非常简单,可快速地在Kubernetes环境中安装软件。
以Kubernetes中的证书管理为例,我们可以参考链接 - https://artifacthub.io/packages/helm/cert-manager/cert-manager ,可以快速地通过几个命令就能完成下载与部署。
我希望大家能注意到:低门槛是吸引用户的重要因素,但真正决定软件长期走向的,是它自身的核心功能。所以,Helm中的软件有三点需要特别关注:
- 契合Kubernetes平台:许多软件原生并不支持Kubernetes,需要做一定的改造;
- 保证常规功能:如安装时要判断依赖项、卸载时清理哪些数据、升降版本兼容性等等,都是很琐碎、又是很重要的事情;
- 人工维护问题:软件是高频迭代的,尤其是在云原生环境下,核心项目往往要大量的人力投入到 FAQ、配置参数说明、兼容性问题的处理;
这三点给Helm带来的是一种滚雪球效应,即越滚越大、越难以被替代;而这种雪球最终能支撑多大的市场,非常依赖Helm内部的核心设计,尤其是扩展性部分。
Charts
Helm称自己是Kubernetes平台中的包管理器,而这个包的格式被称为Charts,我们一起来看看一个官方示例:
1 | wordpress/ |
关键在于三个目录:
- charts - 保存当前chart的依赖子chart
- crds - 这是chart依赖Kubernetes实现软件运行的关键(CRD是k8s可扩展性的一大特色)
- templates - 用来绑定chart自定义参数
换一个视角,这三个文件夹体现了三种能力:
- charts - package能力复用
- crds - 自定义对接Paas平台(k8s)
- templates - 定制化参数
小结
Helm是Kubernetes使用人员需要非常重视的一个产品,它能快速地帮助我们安装与部署软件。
不过,我不建议大家去阅读它的相关源码,它的代码并不优秀;相反地,我更建议大家可以去尝试自己做一个chart(最好能结合自己开发的程序+依赖的中间件,如go程序+redis),这样既能结合Helm实现应用程序的快速部署,又能去实践Kubernetes的CRD。
2022-02-10 CNCF-Buildpacks
Buildpacks是一款对标Docker的镜像打包工具,虽然在CNCF中作为核心项目,但在目前的主流开发场景中用到的并不多。
- 官网 - https://buildpacks.io/
- Github - https://github.com/buildpacks/pack
我们不妨来思考一下Buildpacks与竞品的核心优势:
Buildpacks官网介绍自身的核心特性为3个:Control、Compliance和Maintainability。我们今天挑选两个关键性的特征来聊一聊。
Control - Balanced control between App Devs and Operators.
平衡开发者与运维人员。这个也是Buildpacks对标Docker的最大优势。
刚熟悉Dockerfile的同学,会觉得体验很棒,只需要少数几行就能快速制作出一个镜像;但是,如果你是重度使用的用户,就会有不一样的体验:
- 多应用的Dockerfile中有大量重复、但又有少量定制化的内容(如依赖的软件)
- 由于定制化的内容存在,往往需要开发工程师编写Dockerfile
所以,维护Dockerfile成为了开发工程师很琐碎的工作,而Buildpacks则是希望将部分工作转移给运维人员。但在我看来,这个收益并不明显:
- 现状:大部分的公司会封装一些基础镜像,在基础镜像上的Dockerfile所需要的命令已经很少了,整体的复杂度不会很高;
- 工作平衡:平衡的意义并没有减少整体的工作量,两种角色的人数总量仍不会有大的变化;
- 责任明确:目前大型公司的运维人员越来越少,更强调的是开发人员自己管理应用的整个生命周期;
但换一个角度,Buildpacks理念是可以降低开发人员对Dockerfile这块的门槛,更专注于业务代码的开发。但是,编写Dockerfile这项技能本身难度不高,而且有利于研发自行排查问题,我个人是非常建议开发人员去学习的。
Maintainability - Perform upgrades with minimal effort and intervention.
这一点是Buildpacks的一大特色。
如果你对Docker的镜像底层有一定的了解,会清楚一个镜像就是一层层layer的堆叠;从最上层来看,就是一个完整的操作系统。但如果只对某个layer进行更改,就得销毁老容器、再起一个新的。而Buildpacks则提供了rebase的能力,也就是在运行中的容器中做到快速替换某个layer,而不需要整个重建。
举一个例子,当前运行的容器有层layer是设置环境变量(参考Dockerfile中的ENV指令),我们要进行增加或者更改参数,就能快速实现rebase。当然,rebase肯定是有不少限制条件的,尤其是rebase中的内容不能影响到程序的运行。
我们不妨发散地思考这个特性的价值:由于它核心解决了无需重启整个容器的作用,所以对启动成本比较大的程序,它的意义是很大的,尤其是Java程序。
小结
Buildpacks在社区中活跃度并不高,这也间接证明了Docker的统治地位,而它则需要一个合适的契机才可能得到大幅度的应用。这也提醒了我们,不要一味地追求新的技术,更应该结合现状理性分析。
2022-02-11 CNCF-Operator Framework
Operator Framework是为了降低Kubernetes中Operator开发门槛,而由CNCF社区提供的一套框架。由于这一整套的解决方案门槛很高,需要使用者对Kubernetes的原理有相当的基础,所以今天我们不会深入其细节,而是通过借由这个项目更好地理解Kubernetes。
- 官网 - https://cloud.redhat.com/learn/topics/operators
- Github - https://github.com/operator-framework/operator-sdk
- 公开库 - https://operatorhub.io/
Controller的工作原理
Operator本质上,是一种定制化的Controller;而控制器的核心思想,是根据期望状态与当前状态,管理k8s中的资源。我们这边可以结合下面这张图,来了解Controller的工作原理。
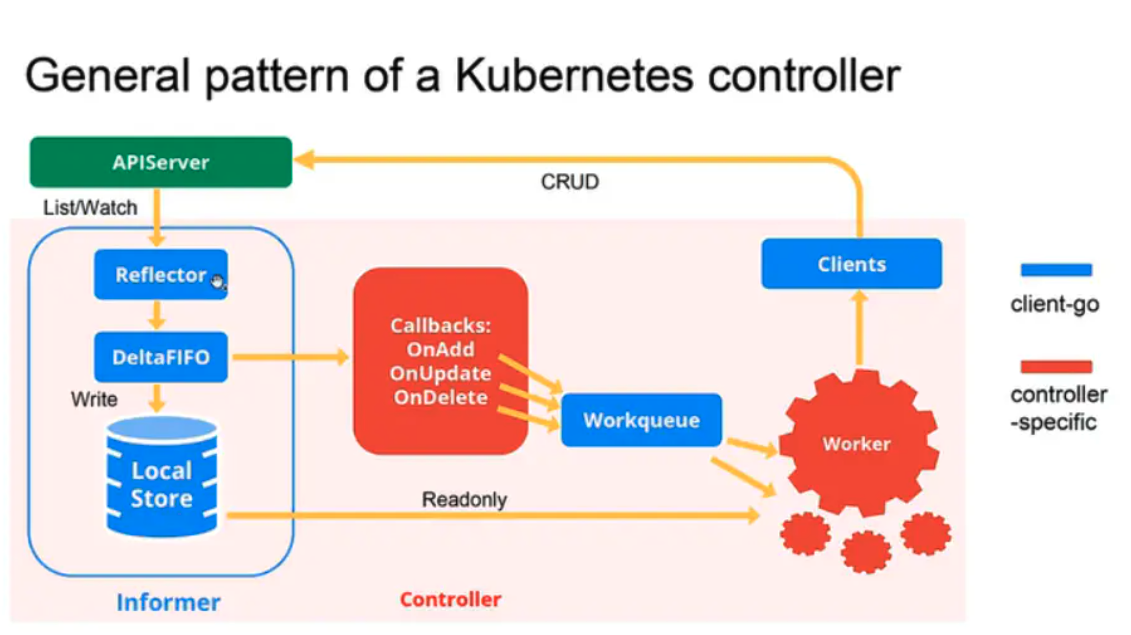
- client-go是k8s提供的代码生成工具,相关的代码会自动生成;而controller-specific是自行开发的内容;
- 期望状态与当前状态的对比逻辑,决策的结果是 新增、更新、删除对应的资源,触发对应的callbacks;
- 具体的执行工作,交给Worker执行,而结果如果未达到预期,依然会再次触发整个流程;
关于k8s中的controller,源码分析可以参考我之前的一篇博客 https://junedayday.github.io/2021/02/18/k8s/k8s-012/
三大组件
- Operator SDK - 快速生成Operator相关代码
- Operator Lifecycle Manager - k8s中的生命周期管理
- Operator Metering - 监控
其中监控部分很重要,能帮助使用人员在复杂的K8s系统中排查问题。
小结
目前Operator Framework虽然在社区比较受欢迎,但使用者往往仅限于k8s的深度用户;而许多大型公司又往往会自行封装k8s,不能完美兼容Operator Framework,导致它的推广很受限。
我个人有三点建议:
- 优先去Helm里搜索成熟应用,不要自行开发Operator;
- 如果有切实的使用需求,优先去公开库 - https://operatorhub.io/ 搜索;
- k8s深度玩家可忽略以上两点~
Github: https://github.com/Junedayday/code_reading
Blog: http://junes.tech/
Bilibili: https://space.bilibili.com/293775192
公众号: golangcoding
