
2022-02-14 CNCF-Argo
Argo是Kubernetes上最受欢迎的工作流引擎,已经有大量的用户群体与软件生态。围绕着Workflow这个关键词,我们来一起初步了解Argo。
Workflow engine for Kubernetes
Argo Workflow
官方的介绍分为四点(前两点描述的是基本原理,后两者描述的是特定应用的价值):
- 工作流的每一个步骤都是一个容器;
- 以DAG(有向无环图)来分析工作流的依赖;
- 对计算密集型任务(如机器学习、大数据处理),能充分利用k8s集群的相对空闲的碎片时间;
- 结合CICD流水线,让应用能运行在云原生环境里快速迭代;
为什么使用Argo Workflow
Argo的工作流对标传统的CICD有很多亮点,但如果谈论其核心价值,主要集中在两点:
- 保证应用的整个生命周期都基于云原生生态,彻底抛弃原来的虚拟机等模式;
- 完全对接云原生,有利于充分利用Kubernetes实现更便捷的并行、扩缩容等操作;
我们就以一个经典的CICD Workflow的发展历程来看:
- 传统Jenkins为核心的CICD
- 提交代码到Gitlab
- 触发Jenkins编译任务,某VM服务器编译出二进制文件并发布
- 触发Jenkins部署任务,将二进制文件发布到对应机器并重新运行程序
- 改进版 - 容器化,将Gitlab/Jenkins/编译服务器等都改造到容器化平台中
- 云原生化 - 利用Argo Workflow
第二与第三阶段的区分并不清晰,我个人会从 配置是否集中化 这个特点进行分析。
目前很多大公司的CICD仍处于第二阶段,但它们沉淀出了不少类似于Argo工作流的能力。我们可以从以下三点进行思考:
- 工作流是和公司强相关的:往往依赖公司内的各种平台,如OA;
- 工作流的开发难度不高:只要规则清晰、要求严格,整体的开发量并不大,所以有能力、有资源的大公司,并不愿意太依赖开源生态;
- 云原生的工作流价值仍比较有限:
Argo体现出的价值,有不少类似的方案可以替代;
小结
Argo项目的用户在社区中日趋增长,这其实体现出了一个趋势 - 互联网进入精耕细作的阶段。
在野蛮生长阶段遇到瓶颈时,公司会趋向于用扩增大量的人力或机器资源来解决问题;而在精耕细作阶段,随着Kubenetes为代表的基础平台能力的标准化,整个生态提供了丰富的能力集,技术人员更应重视遵循规范,把时间投入到合理的方向,来快速地迭代业务。
这时,以Argo为代表的工作流引擎,能帮助整个开发体系落地自动化的规范,自然越来越受到欢迎。
2022-02-15 谈谈对Go接口断言的误区
最近有好几个朋友和我聊到Go语言里的接口interface相关的使用方法,发现了一个常见的误区。今天,我分享一下我的思考,希望能给大家带来启发。
接口与实现
1 | // 接口定义 |
这是一个很常见的接口与实现的示例。
接口断言背后的真正问题
在代码中,我们经常会对抽象进行断言,来获取更详细的信息,例如:
1 | func Foo() { |
这段代码很清晰,让我们层层递进,思考一下这段代码背后的真正逻辑:程序要使用 接口背后的具体实现(orderImpl1中的Id字段)。
这种做法,就和接口所要解决的问题背道而驰了:接口是为了屏蔽具体的实现细节,而这里的代码又回退成了具体实现。所以,这个现象的真正问题是:接口抽象得不够完全。
解法1:新增获取方法
这个解法很直接,我们增加一个接口方法即可,如:
1 | type Order interface { |
但是,如果要区分具体实现,即orderImpl2没有Id字段,我们最好采用一个error字段进行区分:
1 | type Order interface { |
解法2:封装背后的真正逻辑
上面GetId这个方法,只是一个具体动作,按DDD的说法,这是一个贫血的模型。我们真正要关注的是 - 获取Id后真正的业务逻辑,将其封装成一个方法。
比如说,我们要获取这个Id后,想要根据这个Id取消这个订单,那么完全可以封装到一个Cancel()函数中;
又比如说,我们仅仅想要打印具体实现的内部信息,那么完全可以实现一个Debug() string方法,将想要的内容都拼成字符串返回出来。
小结
今天讲的这个case在业务开发中非常常见,它是一种惯性思维解决问题的产物。我们无需苛求所有抽象都要到位,但心里一定要有明确的解决方案。
2022-02-16 CNCF-Flux
今天我们来看CNCF中另一款持续交付的项目 - Flux。相对于Argo,Flux的应用范围不广,但它的功能更加简洁、使用起来也更为便捷。
- 官网 - https://fluxcd.io/
- Github - https://github.com/fluxcd/flux2
核心流程
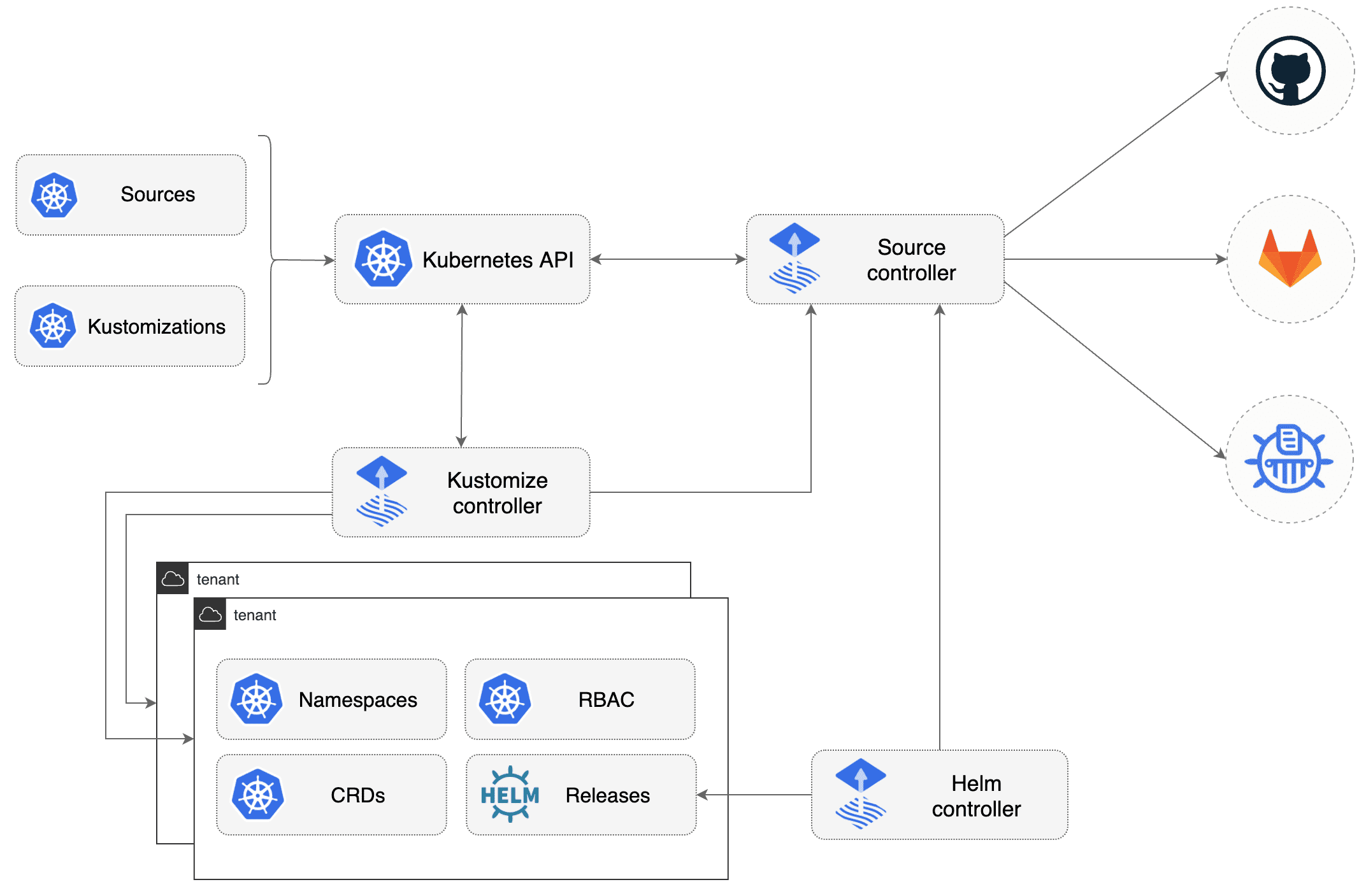
Flux的核心实现非常清晰,主要分为两块:
- Source controller用于监听Source的变化,如常见的github、gitlab、helm;
- 将部署任务,交由Kustomize controller 或 Helm controller进行实现;
这里有一个秀英语单词的技巧,在软件系统里经常会将定制化这个词,Customize用Kustomize代替。
核心概念
官方的核心概念如下:https://fluxcd.io/docs/concepts/
- GitOps的理念有很多说法,可以简单认为就是:围绕着Git而展开的一套CICD机制。
GitOps is a way of managing your infrastructure and applications so that whole system is described declaratively and version controlled (most likely in a Git repository), and having an automated process that ensures that the deployed environment matches the state specified in a repository.
- Source源,包括期望状态与获取的途径。
A Source defines the origin of a repository containing the desired state of the system and the requirements to obtain it (e.g. credentials, version selectors).
- Reconciliation协调,重点是怎么协调、也就是Controller执行的逻辑,最常见的就是自己编写一个Operator。
Reconciliation refers to ensuring that a given state (e.g. application running in the cluster, infrastructure) matches a desired state declaratively defined somewhere (e.g. a Git repository).
小结
CICD相关软件目前的格局还不是很清晰,建议大家多花时间在选型上,尽可能地符合自己的业务场景,而不建议做过多的二次开发。Flux是一个非常轻量级的CD项目,对接起来很方便,很适合无历史包袱的研发团队快速落地。
2022-02-17 自顶向下地写出优雅的Goroutine(上)
Go语言的Goroutine特性广受好评,让初学者也能快速地实现并发。但随着不断地学习与深入,有很多开发者都陷入了对goroutine、channel、context、select等并发机制的迷惑中。
那么,我将自顶向下地介绍这部分的知识,帮助大家形成体系。具体的代码以下面这段为例:
1 | // parent goroutine |
这里的Foo()为父Goroutine,内部开启了一个子Goroutine - SubFoo()。
聚焦核心
父Goroutine 与 子Goroutine 最重要的交集 - 是两者的生命周期管理。包括三种:
- 互不影响 - 两者完全独立
- parent控制children - 父Goroutine结束时,子Goroutine也能随即结束
- children控制parent - 子Goroutine结束时,父Goroutine也能随即结束
这个生命周期的关系,体现了一种控制流的思想。
注意,这个时候不要去关注具体的数据或代码实现,初学者容易绕晕。
1-互不影响
两个Goroutine互不影响的代码很简单,如同示例。
不过我们要注意一点,如果子goroutine需要context这个入参,尽量新建。这点我们看第二个例子就清楚了。
2-parent控制children
下面是一个最常见的用法,也就是利用了context:
1 | // parent goroutine |
当然,context并不是唯一的解法,我们也可以自建一个channel用来通知关闭。但综合考虑整个Go语言的生态,更建议大家尽可能地使用context,这里不扩散了。
延伸 - 如果1个parent要终止多个children时,context的这种方式依然适用。
3-children控制parent
这部分的逻辑也比较直观:
1 | // parent goroutine |
情况3的延伸
如果1个parent产生了n个children时,又会有以下两种情况:
- n个children都结束了,才停止parent
- n个children中有m个结束,就停止parent
其中,前者的最常用的解决方案如下:
1 | // parent goroutine |
关于这两个延伸情况更多的解法,就留给大家自己去思考了,它们有不止一种解法。
小结
从生命周期入手,我们能快速地形成代码的基本结构:
- 互不影响 - 注意context独立
- parent控制children - 优先用context控制
- children控制parent - 一对一时用channel,一对多时用sync.WaitGroup等
但在实际的开发场景中,parent和children的处理逻辑会有很多复杂的情况,导致我们很难像示例那样写出优雅的select等方法,我们会在下期继续分析,但不会影响我们今天梳理出的框架。
2022-02-18 自顶向下地写出优雅的Goroutine(中)
通过上一篇,我们通过生命周期管理了解了父子进程的大致模型。
今天,我们将更进一步,分析优雅的Goroutine的核心语法 - select。
了解select的核心意义
我们看一个官方的例子:
1 | package main |
代码很长,我们聚焦于select这块,它实现了两个功能:
- 传递数据
- 传递停止的信号
这时,如果你深入去理解这两个channel的用法,容易陷入对select理解的误区;而我们应该从更高的维度,去看这两个case中获取到数据后的操作,才能真正掌握。
分析select中的case
我们要注意到,在case里代码运行的过程中,整个goroutine都是忙碌的(除非调用panic,return,os.Exit()等函数退出)。
以上面的代码为例,如果x, y = y, x+y函数的处理耗时,远大于x这个通道中塞入数据的速度,那么这个x的写入处,将长期处于排队的阻塞状态。这时,不适合采用select这种模式。
所以说,select适合IO密集型逻辑,而不适合计算密集型。也就是说,select中的每个case,应尽量花费少的时间。IO密集型常指文件、网络等操作,它消耗的CPU很少、更多的时间在等待返回。
Go 的 select这个关键词,可以结合网络模型中的select进行理解。
父子进程中的长逻辑处理
这时,如果我们的父子进程里,就是有那么一长段的业务逻辑,那代码该怎么写呢?我们来看看下面这一段:
1 | // children goroutine |
由于LongLogic()会花费很长的运行时间,所以当外部的context取消了,也就是父Goroutine发出通知可以结束了,这个子Goroutine是无法快速触发到<-ctx.Done()的,因为它还在跑LongLogic()里的代码。也就是说,子进程生命周期结束的时间点延长到LongLogic()之后了。
所以,根本原因在于违背了我们上面说的原则,即在select的case/default里包含了计算密集型任务。
case里包含长逻辑不代表程序一定有问题,但或多或少地不符合select+channel的设计理念。
两个长逻辑处理
这时,我们再来写个长进程处理,整个代码结构如下:
1 | func SubFoo(ctx context.Context) { |
这时,dataCh和dataCh2会产生竞争,也就是两个通道的 写长期阻塞、读都在等待LongLogic执行完成。给channel加个buffer可以减轻这个问题,但无法根治,运行一段时间依旧阻塞。
改造思路
有了上面代码的基础,改造思路比较直观了,将LongLogic异步化:
1 | // children goroutine |
我们要注意一个点,如果LongLogic()是一段需要CPU密集计算的代码,比如计算1累加到10000,它是没有办法通过channel等其余方式突然中止的。它具备一定的原子性 - 要么不跑,要么跑完,没有Channel的插手的地方。
而如果硬要中断LongLogic(),那就是杀掉整个进程。
小结
今天的内容是围绕着select这个关键词展开的,我们记住select代码块设计的核心要领 - IO密集型。Go语言的goroutine特性,更多地是为了解决IO密集型程序的问题所设计的编程语言,对计算密集型的任务较其它语言很难体现出其价值。
落到具体实践上,就是让每个case中代码的运行时间尽可能地短,快速回到for循环里的select去继续监听各个case中的channel。
上面这段代码比较粗糙,在具体工程中会遇到很多问题,比如无脑地开启了大量的LongLogic()协程。我们会放在最后一讲再来细谈。
Github: https://github.com/Junedayday/code_reading
Blog: http://junes.tech/
Bilibili: https://space.bilibili.com/293775192
公众号: golangcoding
