
2022-01-24 CNCF-Linkerd
今天我们来看 Orchestration & Management 编排和管理 层最后一个核心项目 - Linkerd。从严格意义上来说,我们应称它为Linkerd2,区别于原来的1.0版本。
Linkerd是Service Mesh的第一个产品,但在Google的Istio入场后在功能与性能上完全超越。这一段的历史很有意思,大家可以自行搜索了解。
关于Service Mesh,我们已经聊过两款CNCF中的软件了 - Envoy/Contour,这个Linkerd是两者的结合。我们来看一下它的架构示意图,整体来说分为三块:
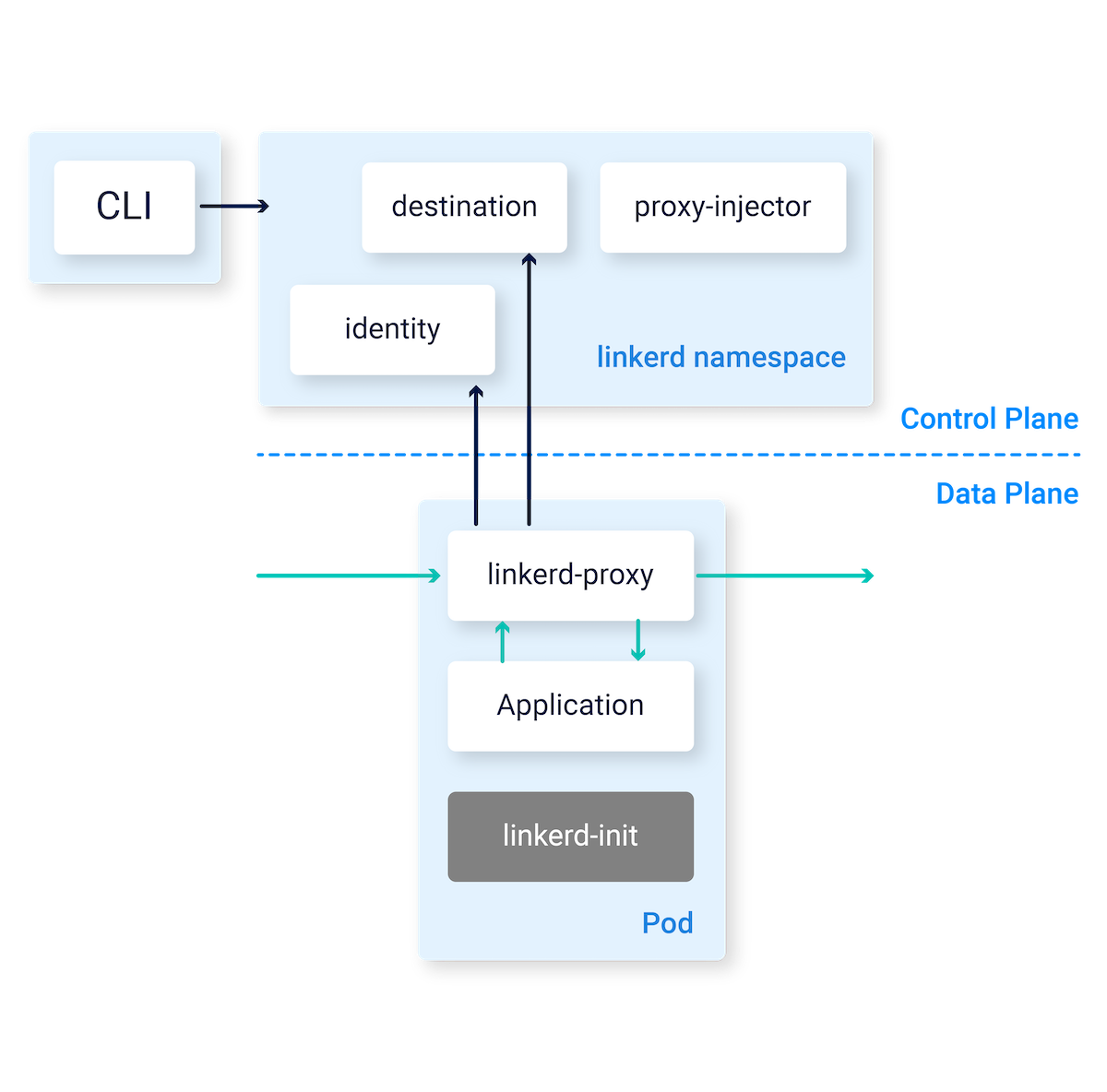
- CLI - 客户端,对Linkerd2进行管理
- Control Plane 控制平面
- destination 获取各类信息,如服务发现、网络策略、性能和监控指标
- indentity 主要是TLS安全相关
- proxy-injector 是一种Kubernetes的Admission Controller,用于对初始化pod注入linkerd相关的信息
- Data Plane 数据平面
- linkerd-proxy 核心的功能实现,包括代理、路由、TLS、限流等等
- linkerd-init 是一种Kubernetes的Init Containter,用iptables的特性将Pod的流量都导向linkerd-proxy
Linkerd的架构非常清晰明了,与Kubernetes的特性紧密结合。我们也不难看到,它的核心能力非常依赖linkerd-proxy这个组件。linkerd-proxy采用了Rust语言编写,而对应的Envoy使用的是C++,从性能来看两者相差无几,更多的是语言生态上的选择不同。
我们再一起读一段Linkerd官方对Service Mesh的定义:
A service mesh like Linkerd is a tools for adding observability, security, and reliability features to “cloud native” applications by transparently inserting this functionality at the platform layer rather than the application layer.
observability - 可观察性:logging、metrics、tracing
security - 安全性:TLS等特性
reliability - 可靠性:体现在对网络层的统一管理
从目前来看,Linkerd仍处于一个比较早期的阶段,对标Istio还有大量的功能缺失,我在短期内不太看好。不过它引入了Rust语言有可能吸引一批优秀的人才,成为突破口。
2022-01-25 Go1.18的两个教程
在1月初,我们已经一起看了Go官方对1.18的新特性讲解,想回顾的朋友可以点击这个链接:Go1.18概览。前几天,官方又发布了对泛型和Fuzzing的两个教程,我们再一起浏览下,查漏补缺。
Generics
1 | func SumIntsOrFloats[K comparable, V int64 | float64](m map[K]V) V { |
- comparable 是个关键词,指的是支持操作符
==和!= - int64 | float64 则用简洁的语法表示了两种支持的类型
但第二点,如果支持的类型太多,就需要做一次抽象,如
1 | type Number interface { |
Go语言的泛型表示方法非常简单,其支持的能力也很有限。相对于C++与JAVA中的泛型,无疑逊色了很多。我们可以简单地归纳Go泛型的使用场景:用于 基础类型 的通用操作,如int/int32/int64/float64等这种重复性很高的基本运算。
作为一种标准,Go的泛型落地非常坎坷,短期内官方也不太可能在这块扩增新的特性,所以Go的泛型适用性会比较窄。
随着1.18的完全落地,我们可以在很多基础库中看到泛型的实践,到时候我们再可以根据具体case进行了解。
Fuzzing
1 | func FuzzReverse(f *testing.F) { |
相对于传统的单元测试,Fuzzing Test更强调一种 不确定性的输入 理念 - 由于输入的数据是随机的,输出往往是不确定的,那我们最好可以通过一定的操作,减少甚至消除输出的不确定性,才能保证测试的完备性:
比如说,示例中对字符串的反转,转变成了两个测试点:
- Reversing a string twice preserves the original value 即两次反转后成为原字符串,
- The reversed string preserves its state as valid UTF-8 字符串依然为UTF-8编码格式
从输入和输出来看,如果每个输入都对应枚举出一个输出,那就是单元测试;而Fuzzing Test的理念是尽可能地将输出做到可控,更方便地写各种测试。
在实际工程中,能用到Fuzzing特性的地方很少,更多的还是依赖简单地单元测试保障我们的代码质量。
2022-01-26 如何避免分布式事务
最近,有朋友和我交流分布式事务的实践心得,而我的建议是:尽量避免分布式事务。
这里的避免并非完全的不要使用,毕竟像金融场景中,这还是一个必要的特性。但对于绝大多数系统,分布式事务带来的复杂度是非常高的,也需要很高的维护成本与理解成本,远超其收益,我不太建议大家刻意地使用这个技术。
举一个简单的case - 用户下了一个订单,经过如下步骤:
- 订单服务生成订单
- 库存服务扣去库存
- 付费服务完成扣款
- 用户积分服务增加积分
这时,最直观的解法是要有一套成熟的分布式事务的方案。但事实上,我更推荐在工程上采用下面两种解决方案,而其中的关键词就是 - 补偿。
在MQ中重试
我们经常会利用MQ来解耦服务,那么自然会用它来驱动大量的消息。
例如,我们将扣款请求放到MQ里,扣款服务处理成功后通过另一个MQ通知成功。而当扣款服务出现问题时、也就是扣款失败,常见的有2种选择:
- 如果要求是必须成功的,消费时就不要返回成功,在服务中反复重试,即便MQ积压产生告警、再人工恢复;
- 如果允许失败,那就设置一个最大重试次数,超过最大重试次数则通知给对应的补偿服务;
利用trace-id+ELK
trace-id是分布式链路追踪的关键信息,用于串联信息;而ELK又通过日志收集系统,将这块收集到了一个系统。
我们可以在生成订单时,同时记录这个关键性的trace-id,然后调用各个服务。有任何一个服务失败,我们就将订单状态修改为失败或超时;而数据不一致的问题,就由对应的补偿服务,根据这些有问题的订单的trace-id去分析。
其实可以从这个方案延伸出类似的,比如直接将错误通过trace-id+信息发送给补偿服务,统一收集。
注意点
- 补偿不代表只能手动,我们可以在补偿服务内根据错误码,实现一定的自动化;
- 补偿更多体现的是一种最终一致性的思想,会有延时,我们要保证中间状态的数据不会污染系统;
在微服务+云原生时代,我们非常提倡 面向错误编程,正是为了能更好地面对各种不确定的异常case。分布式事务带来了大量的复杂度,目前也没有一套跨语言、跨组件的通用解决方案,目前主流几个方案对应用的侵入性很强,所以我不太建议大部分朋友在生产环境使用,而花更多时间学习相关理论、应付面试就行了。
2022-01-27 CNCF-TiKV
了解完核心的 调度与管理 相关的软件后,我们接下来开始接触 应用定义与开发 的相关软件,这部分与我们实际开发接触最为紧密,也更容易理解。
- 官网 - https://tikv.org/
- Github - https://github.com/tikv/tikv
官方的定义为:
TiKV provides both raw and ACID-compliant transactional key-value API, which is widely used in online serving services, such as the metadata storage system for object storage service, the storage system for recommendation systems, the online feature store, etc.
也就是TiKV支持 简单的与满足ACID事务性的KV存储,被应用在各种存储系统上,如关系型数据库、非关系型数据库、分布式文件系统,最具有代表性的即同属一个公司的TiDB。按官方的定义,我们可以将它对标Redis。
我们结合TiKV的核心特性来看看。
Low and stable latency
RawKV’s average response time less than 1 ms (P99=10 ms).
延迟是IO相关的软件很重要的特性。但对于这个特性,我们要注意两点:
- 只针对简单KV,而不针对事务
- 真实延迟很依赖存储介质
从这点来看,在TiKV层面引入事务的特性前,需要我们要斟酌一下它对延迟的影响。
High scalabilit
With the Placement Driver and carefully designed Raft groups, TiKV excels in horizontal scalability and can easily scale to 100+ terabytes of data. Scale-out your TiKV cluster to fit the data size growth without any impact on the application.
强调了高扩展性,可支持100TB+的数据。
TiKV采用了Raft作为分布式一致性的协议,这一点与Etcd一致。关于Raft这块是目前工程化的主流,相对于Paxos更容易落地。不过,各家在实现Raft时都或多或少有一些变种,这块我们暂时不细聊。
Consistent distributed transactions
Similar to Google’s Spanner, TiKV (TxnKV mode) supports externally consistent distributed transactions.
支持一致性的分布式事务。
分布式事务对强一致性的业务非常有价值,但它的实现必然会带来一定的性能问题,尤其体现在延迟上。以金融服务为例,分布式事务能保证资金的一致性,不产生资损;但延迟问题又会带来一些异常case,所以需要做好权衡。
Adjustable consistency
In RawKV and TxnKV modes, you can customize the balance between consistency and performance.
对简单KV模式与事务性的KV模式,提供了可调节的一致性功能。
这就是一致性与性能上的权衡。关于这点,大家可以了解一下ACID与BASE对业务的价值。从我的观察来看,目前越来越多的服务倾向于最终一致性,主要有以下优点:
- 对外部服务来说视角清晰,更容易理解 - 从外部服务视角来看,本服务最终会趋于一致,而不需要关心各种异常的中间状态,这非常有助于微服务的边界划分;
- 服务更具健壮性 - 软件系统的不稳定因素很多,最终一致性可以更好地处理这些异常。
当然,对应的代价是该服务需要引入重试、幂等、异步校验、状态机、恢复日志等特性,自身的复杂度是比较高的。这些技术我也会在后面和大家分享。
2022-01-28 CNCF-Vitess
今天我们来聊聊一款和关系型数据库相关的产品 - Vitess。Vitess的定位很简洁:
A database clustering system for horizontal scaling of MySQL
我们直接从架构图入手,来了解它是怎么实现 MySQL横向扩展 的。
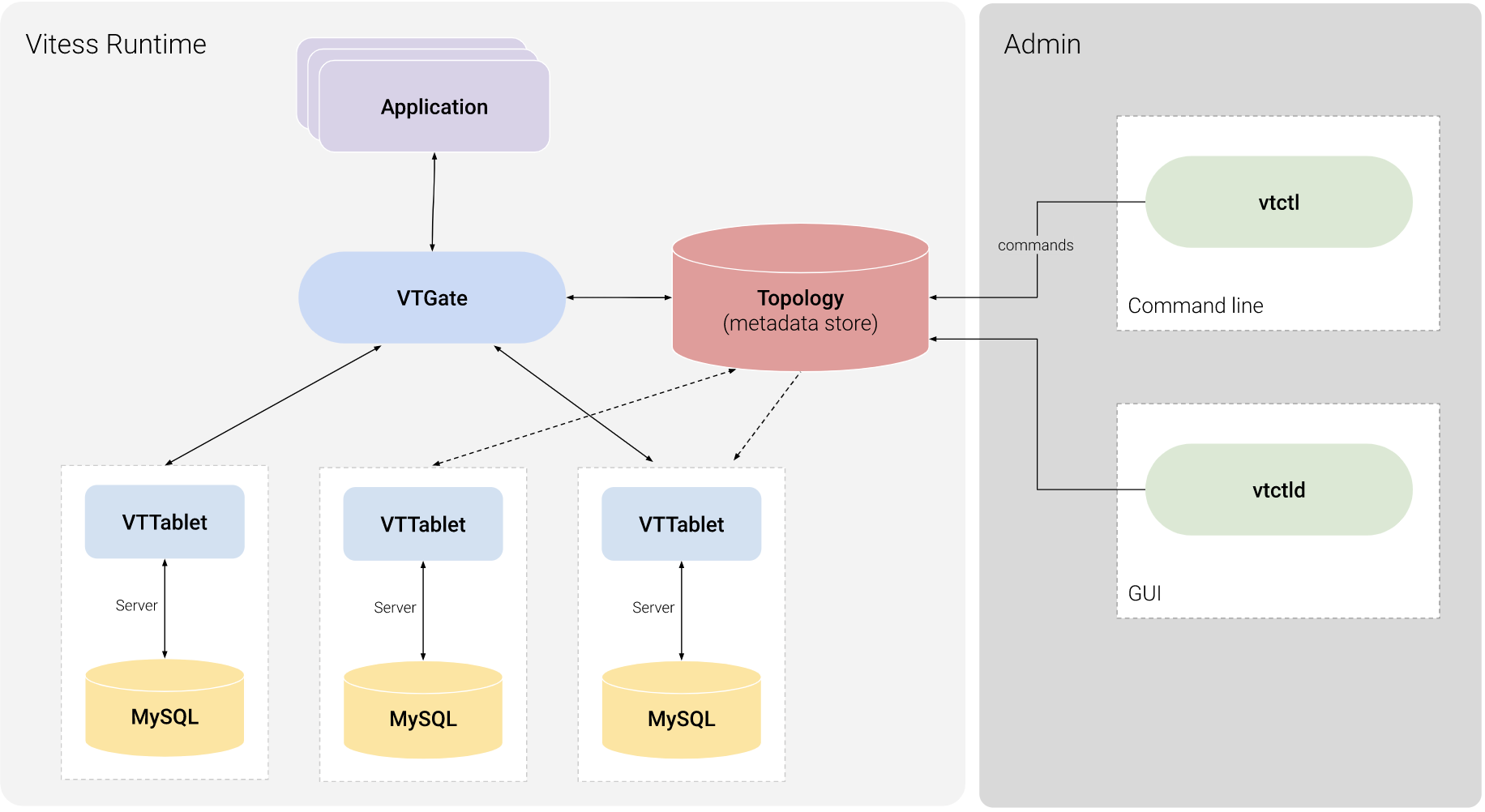
我们关注最核心的两个模块:
VTTablet
A tablet is a combination of a
mysqldprocess and a correspondingvttabletprocess, usually running on the same machine. Each tablet is assigned a tablet type, which specifies what role it currently performs.
一个Tablet对应到一个具体的MySQL实例,类似于sidecar模式。我之前基于VTTablet做过一定的二次开发,和大家分享一下我对这块的认识:
VTTablet最核心实现,是 模拟一个MySQL,与真正的MySQL进行连接。所以,可以体现如下的特点:
- 无侵入式 - 充分利用了MySQL集群间通信的协议,不会侵入原MySQL。这点能衍生出很多价值,例如兼容多版本的MySQL。
- 性能较优 - 通过MySQL内部通信的协议交互。
- 可扩展性强 - 从原先对大MySQL集群的维护,转变成了相对轻量级的
VTTablet集群的维护
VTGate
VTGate is a lightweight proxy server that routes traffic to the correct VTTablet servers and returns consolidated results back to the client. It speaks both the MySQL Protocol and the Vitess gRPC protocol. Thus, your applications can connect to VTGate as if it is a MySQL Server.
VTGate是网关层的角色,主要分三块功能:
- 对外暴露出原生的MySQL协议与gRPC协议;
- 对内维护与
VTTablet集群的连接; - 核心依赖Topology服务中的数据,主要是
VTTablet的状态数据和Admin的配置数据
小结
Vitess是用Go语言编写的软件,我比较推荐对数据库原理感兴趣的朋友去阅读VTTablet相关的源码,从中你可以了解到很多MySQL的关键性功能,会比直接阅读MySQL的C++简单很多。比如我曾经做过的:
- SQL解析 - 用于自研的查询平台
- Binlog同步 - 用于MySQL到异构数据库的同步平台
Github: https://github.com/Junedayday/code_reading
Blog: http://junes.tech/
Bilibili: https://space.bilibili.com/293775192
公众号: golangcoding
